
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 백준
- Baekjoon
- 코딩
- Elasticsearch
- database
- 엘라스틱서치
- Java
- kotlin
- ES
- 개발자
- 스프링
- 데이터베이스
- 그리디
- framework
- 애자일기법
- 개발
- 애자일프로그래밍
- 알고리즘
- 코딩테스트
- API
- spring boot
- 그리디알고리즘
- JPA
- cleancode
- 코드
- Spring
- 프레임워크
- 읽기쉬운코드
- 클린코드
- 자바
- Today
- Total
튼튼발자 개발 성장기🏋️
카프카 스트림즈 본문
1. 카프카 스트림즈란?
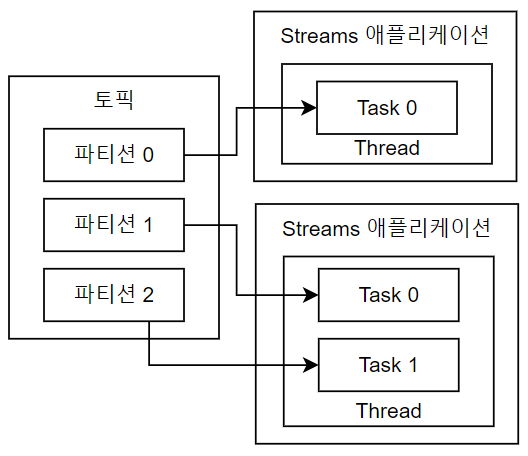
카프카 스트림즈(Kafka Streams)는 카프카에서 스트리밍 데이터를 실시간으로 처리하고 분석하기 위한 자바 라이브러리다. 기존의 데이터 처리 시스템과는 달리, 카프카 스트림즈는 데이터가 들어오는 즉시 이를 처리하고 결과를 다시 카프카 토픽에 기록할 수 있다. 카프카 스트림즈는 MSA 아키텍처에 적합하며, 높은 처리량과 확장성을 제공한다. 스트림즈 애플리케이션은 스레드를 1개 이상 생성할 수 있으며, 스레드는 1개 이상의 태스크(Task)를 갖는다.이 태스크의 수는 파티션의 수와 일치하도록 한다. 기본적으로 라이브환경에서는 안정적으로 운영할 수 있도록 2개 이상의 서버로 구성하여 스트림즈 애플리케이션을 운영한다.
1.1 KStreams
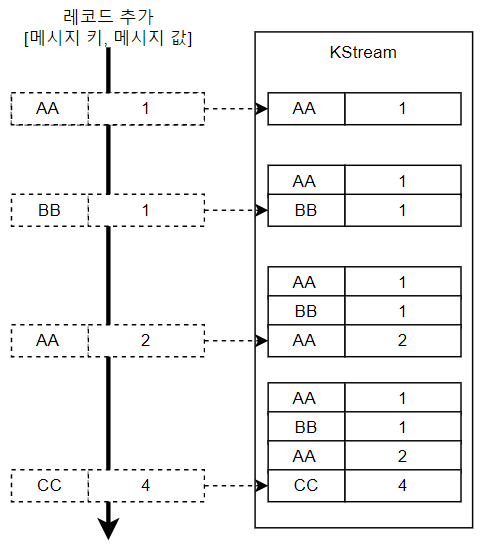
KStreams는 카프카 스트림즈에서 가장 기본이 되는 스트림(Stream)이다. KStream은 레코드(키-값 쌍)의 연속적인 흐름을 나타내며, 실시간으로 데이터를 처리하는 데 사용된다. KStream은 주로 필터링, 매핑, 집계 등의 연산을 수행할 수 있으며, 데이터가 계속해서 들어오는 상황에서 적합한 처리를 할 수 있다. 예를 들어, 특정 토픽에서 데이터를 읽어와서 필터링하고, 다른 토픽에 저장하는 간단한 스트림 처리를 생각할 수 있다.
예제 코드
KStream<String, String> stream = builder.stream("input-topic");
KStream<String, String> filteredStream = stream.filter((key, value) -> value.contains("filter-word"));
filteredStream.to("output-topic");1.2 KTable

KTable은 카프카 스트림즈에서 테이블(Table) 개념을 모델링한 것이다. KTable은 특정 시점의 데이터를 나타내며, 기본적으로 레코드의 최종 상태를 유지한다. 즉, 같은 키에 대해 여러 번의 업데이트가 있을 경우, KTable에는 마지막으로 업데이트된 값만 남는다. KTable은 주로 집계 작업에 사용되며, 상태를 유지해야 하는 상황에서 유용하다. 예를 들어, 사용자별로 총 구매 금액을 계산하는 경우, KTable을 사용할 수 있다.
예제 코드
KTable<String, Long> purchases = builder.table("purchases-topic");
KTable<String, Long> totalPurchases = purchases.groupBy((userId, purchase) -> KeyValue.pair(userId, purchase))
.reduce(Long::sum);1.3 GlobalKTable

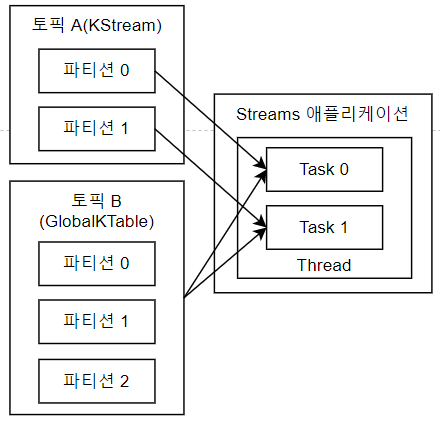
GlobalKTable은 KTable과 유사하지만, 클러스터 내의 모든 인스턴스에 동일한 데이터가 복제되어 유지되는 테이블이다. GlobalKTable은 모든 애플리케이션 인스턴스에서 동일한 데이터를 참조할 필요가 있는 상황에서 주로 사용된다. 예를 들어, 모든 인스턴스가 참조할 수 있는 공통된 참조 데이터나 정적 데이터를 저장하는 데 유용하다. GlobalKTable은 주로 KStream과 조인(Join)하여 사용된다. 조인 연산을 통해 GlobalKTable에 있는 데이터를 KStream의 레코드와 결합하여 더 풍부한 정보를 생성할 수 있다.
코파티셔닝(Co-partitioning)과 리파티셔닝(Repartitioning)
GlobalKTable과 KStream을 조인할 때 중요한 개념 중 하나가 코파티셔닝(Co-partitioning)과 리파티셔닝(Repartitioning)이다.
- 코파티셔닝(Co-partitioning): 코파티셔닝이란, 두 개 이상의 카프카 토픽이 동일한 파티셔닝 스키마를 따르는 것을 의미한다. 즉, 동일한 키를 가진 레코드가 동일한 파티션에 위치하도록 파티셔닝이 일치하는 것이다. KTable과 KStream을 조인할 때, 두 데이터 스트림이 코파티셔닝되어 있으면, 동일한 파티션에서 데이터를 처리할 수 있어 조인이 효율적이고 빠르게 이루어진다.
- 리파티셔닝(Repartitioning): 두 스트림이 코파티셔닝되어 있지 않다면, 조인 작업 전에 리파티셔닝이 필요할 수 있다. 리파티셔닝은 데이터를 새로운 파티션 구조로 재분배하는 과정을 말한다. 리파티셔닝은 추가적인 네트워크 비용과 지연을 초래할 수 있기 때문에, 가능하다면 피하는 것이 좋다. 특히 KStream과 KTable의 조인에서 리파티셔닝이 필요하면, 스트림즈 애플리케이션의 성능에 부정적인 영향을 미칠 수 있다.
그러나 GlobalKTable은 클러스터의 모든 인스턴스에 동일한 데이터를 복제하고 유지하기 때문에, 코파티셔닝이 필요하지 않을 수 있다. GlobalKTable은 파티션 간에 데이터가 동일하게 복제되므로, 모든 인스턴스에서 언제든지 참조할 수 있다. 따라서 GlobalKTable과 KStream을 조인할 때는 리파티셔닝 과정이 생략되며, 이로 인해 성능 상의 이점이 있다. 이러한 이유로, GlobalKTable은 상대적으로 작은 크기의 정적 데이터를 저장하거나, 애플리케이션 전반에 걸쳐 참조해야 하는 공통 데이터를 저장하는 데 적합하다. GlobalKTable을 활용하면, 애플리케이션의 복잡성을 줄이고 성능을 최적화할 수 있다.
예제 코드
GlobalKTable<String, String> productDetails = builder.globalTable("product-details-topic");
KStream<String, String> purchases = builder.stream("purchases-topic");
KStream<String, String> enrichedPurchases = purchases.join(productDetails,
(purchaseKey, purchaseValue) -> purchaseKey,
(purchaseValue, productDetailValue) -> purchaseValue + ", Details: " + productDetailValue);2. 스트림즈DSL
카프카 스트림즈에서 제공하는 스트림즈DSL(Streams DSL)은 스트리밍 데이터를 쉽게 처리할 수 있도록 도와주는 고수준의 API다. 스트림즈DSL은 스트림 연산을 함수형 프로그래밍 스타일로 작성할 수 있도록 하며, 이를 통해 복잡한 데이터 처리를 간결하게 표현할 수 있다.
2-1. 스트림즈DSL의 주요 옵션
스트림즈DSL에서는 다양한 옵션을 제공하여 스트리밍 데이터를 처리할 수 있다. 주요 옵션으로는 stream(), table(), globalTable() 등이 있으며, 각각 스트림, 테이블, 글로벌 테이블을 생성하는 역할을 한다. 또한, filter(), map(), flatMap() 등의 다양한 연산을 제공하여 데이터를 필터링하고 변환할 수 있다.
2-2. stream().to()
stream().to()는 KStream을 특정 카프카 토픽으로 전송하는 데 사용된다. 이 연산을 통해 실시간으로 처리된 데이터를 카프카의 다른 토픽에 기록할 수 있다.
2-3. filter()
filter()는 스트림의 레코드를 필터링하는 데 사용된다. 주어진 조건에 맞는 레코드만 남기고 나머지는 제거한다.
2-4. KTable과 KStream 조인
KTable과 KStream을 조인(Join)하면 스트림과 테이블 간의 결합된 데이터를 처리할 수 있다. 이는 주로 스트림의 레코드를 KTable의 상태와 결합하여 분석하거나 처리할 때 사용된다.
2-5. GlobalKTable과 KStream 조인
GlobalKTable과 KStream을 조인하는 것은 KTable과의 조인과 유사하지만, GlobalKTable은 클러스터 내 모든 인스턴스에 동일한 데이터를 유지하므로, 모든 인스턴스에서 동일한 데이터를 참조할 수 있다.
예제 코드
토픽의 문자열 길이가 5이상인 데이터를 필터링해서 다른 토픽으로 저장하는 스트림즈DSL이다.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Properties;
public class KafkaStreamsFilterExample {
public static void main(String[] args) {
// 카프카 스트림즈 설정
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-filter-example");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
StreamsBuilder builder = new StreamsBuilder();
// input-topic에서 스트림을 생성
KStream<String, String> stream = builder.stream("input-topic");
// 문자열 길이가 5 이상인 메시지 필터링
KStream<String, String> filteredStream = stream.filter((key, value) -> value.length() >= 5);
// 결과를 output-topic으로 전송
filteredStream.to("output-topic");
// 스트림즈 애플리케이션 시작
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
// 종료 훅을 추가하여 애플리케이션 종료 시 클린업
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
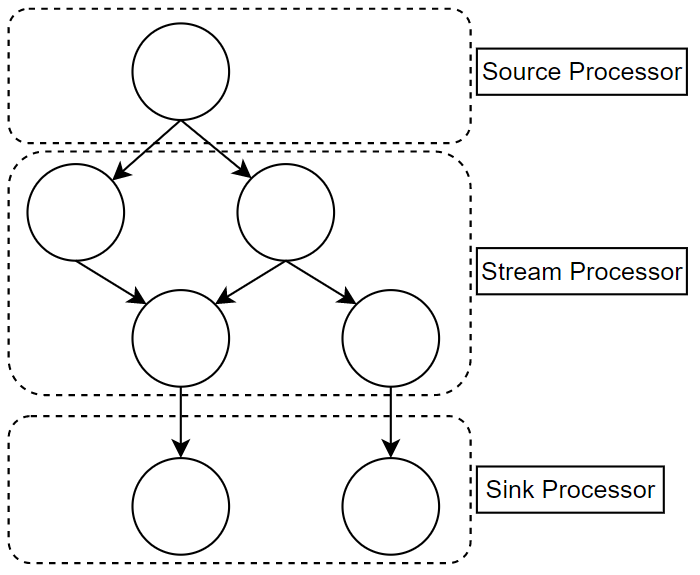
3. 프로세서 API
카프카 스트림즈에서 제공하는 또 다른 강력한 도구는 프로세서 API(Processor API)다. 이 API는 스트림즈DSL보다 더 낮은 수준에서 스트림 처리를 제어할 수 있도록 해준다. 프로세서 API를 사용하면 각 레코드에 대해 사용자 정의 처리를 수행하거나, 특정 연산을 더욱 세밀하게 제어할 수 있다.
프로세서 API는 Processor, Transformer, StateStore 등을 사용하여 구현할 수 있으며, 주로 복잡한 상태 관리가 필요하거나 DSL로 표현하기 어려운 연산을 수행할 때 사용한다.
예제 코드
토픽의 문자열 길이가 5이상인 데이터를 필터링해서 다른 토픽으로 저장하는 프로세서 api의 예제다.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.processor.AbstractProcessor;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
import org.apache.kafka.streams.processor.TopologyBuilder;
import org.apache.kafka.streams.processor.api.ProcessorSupplier;
import java.util.Properties;
public class KafkaProcessorExample {
public static void main(String[] args) {
// 카프카 스트림즈 설정
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "processor-api-example");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// Topology를 정의
StreamsBuilder builder = new StreamsBuilder();
Topology topology = new Topology();
topology.addSource("Source", "input-topic")
.addProcessor("Process", new ProcessorSupplier<String, String>() {
@Override
public Processor<String, String> get() {
return new LengthFilterProcessor();
}
}, "Source")
.addSink("Sink", "output-topic", "Process");
// 스트림즈 애플리케이션 생성 및 시작
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
// 종료 훅을 추가하여 애플리케이션 종료 시 클린업
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
// 사용자 정의 프로세서
public static class LengthFilterProcessor extends AbstractProcessor<String, String> {
@Override
public void process(String key, String value) {
if (value != null && value.length() >= 5) {
// 조건을 만족하는 경우, 다음 단계로 전달
context().forward(key, value);
}
// 조건을 만족하지 않으면 값을 전달하지 않음
}
}
}
'기타 > apache kafka' 카테고리의 다른 글
| Kafka MirrorMaker 2 (0) | 2024.08.17 |
|---|---|
| 카프카 커넥트 (1) | 2024.08.17 |
| 카프카 클라이언트 (0) | 2024.08.10 |
| 아파치 카프카란? (1) | 2024.08.05 |
| Apache Kafka의 탄생 배경과 왜 사용해야하는가? (0) | 2024.08.03 |


