
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 스프링
- 백준
- framework
- 코딩테스트
- 데이터베이스
- API
- 그리디
- 개발
- 클린코드
- 알고리즘
- 읽기쉬운코드
- 개발자
- 자바
- 애자일프로그래밍
- 코딩
- Java
- Spring
- 그리디알고리즘
- spring boot
- kotlin
- ES
- JPA
- 프레임워크
- cleancode
- database
- Elasticsearch
- Baekjoon
- 엘라스틱서치
- 애자일기법
- 코드
- Today
- Total
튼튼발자 개발 성장기🏋️
카프카 클라이언트 본문
카프카 클라이언트는 카프카 브로커와 상호 작용하기 위한 다양한 API를 제공한다. 클라이언트는 프로듀서, 컨슈머, 관리자 등 역할에 따라 세분화되어 있으며, 각 클라이언트는 특정 기능을 수행한다. 이번 포스트에서는 이들 클라이언트가 어떻게 동작하며, 어떤 기능을 제공하는지에 대한 내용을 작성한다.
Producer API
Producer API는 데이터를 카프카 브로커에 보내는 역할을 한다. 데이터를 생성하여 특정 토픽에 메시지를 발행하는 역할을 하며, 다양한 설정 옵션을 통해 메시지 전송의 신뢰성, 성능, 순서를 조정할 수 있다.
[그림 1]과 같이 프로듀서가 send()를 호출한다고해서 바로 전달되는 것이 아니다. 파티셔너로부터 어떤 토픽의 파티션으로 전달할지 정해진다. 현재는 기본 파티셔너는 UniformStickyPartitional이 제공된다. 이 파티셔너의 특징은 배치인데, 레코드가 일정 배치가 가득 찼을 때 Sender로부터 카프카 클러스터에 레코드가 전달되는 형태다.

주요 기능
- 토픽에 메시지 발행: Producer는 특정 토픽에 레코드를 전송합니다. 레코드는 메시지 키와 메시지 값, 타임스탬프 및 오프셋으로 구성되며, 메시지 키를 기준으로 파티션이 결정된다.
- 동기/비동기 전송: 레코드는 동기 또는 비동기로 전송될 수 있으며, 비동기 전송 시 전송 성능이 높아지지만 레코드 중복 처리 혹은 유실 등 이슈로인해 신뢰성 관리가 필요하다.
- 메시지 재전송: 전송 실패 시 재전송을 시도할 수 있으며, 이를 통해 메시지 손실을 최소화할 수 있다.
- 데이터 압축: 네트워크 효율을 높이기 위해 메시지를 압축하여 전송할 수 있지만, cpu 및 memory를 사용하는만큼 환경에따라 압출 사용 여부를 결정해야한다.
필수 옵션
bootstrap.servers
- 설명: 카프카 클러스터의 브로커 리스트를 지정한다. 이 옵션을 통해 프로듀서는 클러스터에 연결할 수 있다.
- 형식: <브로커 주소>:<포트> 형식으로 지정한다. 여러 브로커를 쉼표로 구분하여 나열할 수 있다.
- 예시: bootstrap.servers=localhost:9092,localhost:9093
key.serializer
- 설명: 메시지 키를 직렬화할 방법을 지정한다. 프로듀서가 메시지 키를 바이트 배열로 변환할 때 사용된다.
- 형식: 직렬화 클래스 이름을 지정한다.
- 예시: key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer
- 설명: 메시지 값을 직렬화할 방법을 지정한다. 프로듀서가 메시지 값을 바이트 배열로 변환할 때 사용한다.
- 형식: 직렬화 클래스 이름을 지정한다.
- 예시: value.serializer=org.apache.kafka.common.serialization.StringSerializer
선택 옵션
acks
- 설명: 프로듀서가 브로커로부터 전송된 메시지에 대한 확인 응답을 기다리는 방식을 지정한다. 이는 메시지의 내구성과 전송 신뢰성에 영향을 줄 수 있다.
- 옵션 값:
- acks=0: 프로듀서는 브로커의 응답을 기다리지 않고 메시지를 전송한다.
- acks=1: 리더 브로커가 메시지를 받으면 응답을 보낸다.
- acks=all 또는 acks=-1: 리더와 모든 팔로워 브로커가 메시지를 받았을 때 응답한다. 내구성이 가장 높다.
- 기본값: acks=1
retries
- 설명: 메시지 전송이 실패할 경우, 프로듀서가 재시도할 횟수를 지정한다. 이 옵션은 일시적인 오류가 발생했을 때 메시지 손실을 방지한다.
- 기본값: retries=2147483647 (무한 재시도)
batch.size
- 설명: 프로듀서가 메시지를 묶어서 배치로 전송할 때, 하나의 배치에 포함될 최대 메시지 크기를 바이트 단위로 지정한다. 배치로 전송하면 네트워크 효율이 증가하지만, 지연 시간이 발생할 수 있다.
- 기본값: batch.size=16384 (16KB)
linger.ms
- 설명: 프로듀서가 배치를 채우기 위해 메시지를 기다리는 시간(ms)을 지정한다. 이 시간이 지나면 배치가 채워지지 않아도 메시지를 전송한다. 이를 통해 배치 크기를 늘려 성능을 최적화할 수 있다.
- 기본값: linger.ms=0
compression.type
- 설명: 메시지를 전송하기 전에 압축할지 여부와 방법을 지정한다. 압축을 통해 네트워크 대역폭을 절약할 수 있지만, CPU 사용량이 증가할 수 있다.
- 옵션 값:
- none: 압축하지 않음
- gzip: Gzip 압축
- snappy: Snappy 압축
- lz4: LZ4 압축
- zstd: Zstandard 압축
- 기본값: compression.type=none
client.id
- 설명: 프로듀서를 식별하는 데 사용되는 클라이언트 ID를 지정한다. 이 값은 로깅 및 모니터링에 사용된다.
- 기본값: 빈 문자열(자동 생성)
max.in.flight.requests.per.connection
- 설명: 한 번에 전송할 수 있는 요청의 최대 수를 지정한다. 이 값이 클수록 처리량이 높아지지만, 메시지 순서 보장이 어려워질 수 있다.
- 기본값: max.in.flight.requests.per.connection=5
enable.idempotence
- 설명: 프로듀서가 동일한 메시지를 중복하여 전송하지 않도록 하는 idempotence 모드를 활성한다. 이 옵션이 활성화되면 중복 메시지 전송이 방지된다.
- 기본값: enable.idempotence=false
사용 예제
"my-topic"이라는 토픽에 "key"와 "value"로 구성된 메시지를 전송하는 간단한 예제를 작성해본다.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("my-topic", "key", "value"));
producer.close();
Consumer API
Consumer API는 카프카 토픽에서 메시지를 소비하는 역할을 한다. 컨슈머는 특정 토픽의 메시지를 읽어들여 처리하며, 그룹 단위로 메시지를 관리하여 효율적으로 데이터를 처리할 수 있다.
레코드 소비에 대해서 컨슈머 그룹 간의 간섭이 존재하지 않는다는 장점이 있다. 하나의 컨슈머 그룹에서 컨슈머가 장애가 발생되어 동작을 하지않으면 어떨까? 바로 잡아야하겠지만 호들갑 떨 필요는 없다. 카프카는 자동으로 리벨런싱이라는 기능을 제공해준다. 리벨런싱은 컨슈머가 추가되거나 제거되었을 때 동작한다.
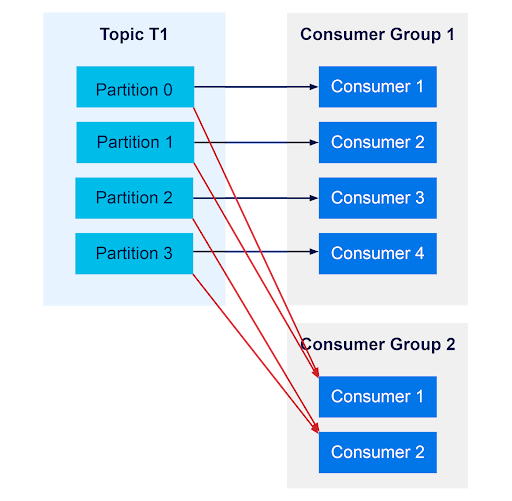

주요 기능
- 메시지 소비: Consumer는 카프카 토픽으로부터 메시지를 읽어들이며, 여러 컨슈머가 하나의 토픽을 동시에 소비할 수 있다.
- 오프셋 관리: Consumer는 메시지를 소비한 위치(오프셋)를 관리하여, 중복된 메시지 소비를 방지하거나 중단된 곳부터 다시 메시지를 소비할 수 있다.
- 컨슈머 그룹: 여러 Consumer를 그룹으로 묶어 작업을 분산 처리할 수 있다. 이 경우 카프카는 파티션을 자동으로 할당하여 각 컨슈머가 고유한 파티션을 처리하도록 한다.
필수 옵션
bootstrap.servers
- 설명: 카프카 클러스터의 브로커 리스트를 지정한다. 컨슈머는 이 주소를 통해 카프카 클러스터에 연결한다.
- 형식: <브로커 주소>:<포트> 형식으로 지정하며, 여러 브로커를 쉼표로 구분하여 나열할 수 있다.
- 예시: bootstrap.servers=localhost:9092,localhost:9093
group.id
- 설명: 컨슈머가 속한 컨슈머 그룹을 식별하는 데 사용된다. 동일한 그룹에 속한 컨슈머들은 서로 협력하여 토픽의 파티션을 나누어 메시지를 소비한다. 이 옵션은 필수이며, 설정하지 않을 경우 컨슈머는 클러스터로부터 메시지를 소비할 수 없다.
- 형식: 문자열로 그룹 ID를 지정한다.
- 예시: group.id=my-consumer-group
key.deserializer
- 설명: 카프카로부터 받은 메시지의 키를 역직렬화할 방법을 지정한다. 이 클래스는 바이트 배열을 원래의 데이터 타입으로 변환하는 데 사용된다.
- 형식: 역직렬화 클래스 이름을 지정한다.
- 예시: key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer
- 설명: 카프카로부터 받은 메시지의 값을 역직렬화할 방법을 지정한다. 이 클래스는 바이트 배열을 원래의 데이터 타입으로 변환하는 데 사용된다.
- 형식: 역직렬화 클래스 이름을 지정한다.
- 예시: value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
선택 옵션
auto.offset.reset
- 설명: 컨슈머가 처음 시작하거나, 현재 오프셋을 찾을 수 없는 경우(예: 오프셋이 삭제되었거나 컨슈머가 처음 시작될 때) 어느 위치에서부터 메시지를 소비할지 결정한다.
- 옵션 값:
- earliest: 토픽의 가장 처음부터 메시지를 소비한다.
- latest: 토픽의 가장 최근 메시지부터 소비한다.
- none: 이전 오프셋이 존재하지 않으면 예외를 던진다.
- 기본값: latest
enable.auto.commit
- 설명: 컨슈머가 주기적으로 오프셋을 자동으로 커밋할지 여부를 지정한다. 이 옵션이 활성화되면 컨슈머는 메시지를 소비한 후 일정 간격으로 자동으로 오프셋을 커밋한다. 컨슈머가 장애가 발생하면 커밋이 안될 수 있기 때문에, 순서가 중요하거나 중복처리되면 안되는 작업에는 사용하지 말아야한다.
- 옵션 값:
- true: 자동 커밋을 활성화한다.
- false: 자동 커밋을 비활성화하고, 프로그래머가 수동으로 오프셋을 커밋해야 한다.
- 기본값: true
auto.commit.interval.ms
- 설명: 자동 커밋이 활성화된 경우, 컨슈머가 오프셋을 커밋하는 주기를 밀리초 단위로 지정한다.
- 기본값: auto.commit.interval.ms=5000 (5초)
fetch.min.bytes
- 설명: 브로커가 컨슈머에게 데이터를 반환하기 전에 모아야 하는 최소 바이트 수를 지정한다. 이 값을 크게 설정하면 한 번에 더 많은 데이터를 가져와 네트워크 효율이 증가하지만, 지연 시간이 늘어날 수 있다.
- 기본값: fetch.min.bytes=1
fetch.max.wait.ms
- 설명: 브로커가 fetch.min.bytes 크기만큼의 데이터를 모으기 위해 기다리는 최대 시간을 밀리초 단위로 지정한다. 이 시간이 지나면 모은 데이터가 최소 크기에 도달하지 못했더라도 반환된다.
- 기본값: fetch.max.wait.ms=500 (0.5초)
max.poll.records
- 설명: 컨슈머가 한 번의 호출로 가져올 수 있는 최대 레코드 수를 지정한다. 이 값을 줄이면 컨슈머는 더 자주 데이터를 가져오게 되지만, 한 번에 가져오는 데이터량이 줄어든다.
- 기본값: max.poll.records=500
session.timeout.ms
- 설명: 컨슈머 그룹에서 컨슈머가 실패했다고 간주되기까지의 시간을 밀리초 단위로 지정한다. 이 시간 내에 컨슈머는 하트비트를 보내야 하며, 그렇지 않으면 컨슈머는 그룹에서 제거된다.
- 기본값: session.timeout.ms=10000 (10초)
heartbeat.interval.ms
- 설명: 컨슈머가 컨슈머 그룹 코디네이터에게 하트비트를 보내는 주기를 지정한다. 이 주기는 session.timeout.ms 값보다 짧아야 한다.
- 기본값: heartbeat.interval.ms=3000 (3초)
client.id
- 설명: 컨슈머 클라이언트를 식별하는 문자열을 지정한다. 이 값은 모니터링 및 로깅에 사용된다.
- 기본값: 빈 문자열 (자동 생성)
partition.assignment.strategy
- 설명: 컨슈머 그룹 내에서 파티션을 컨슈머에 할당하는 전략을 지정한다.
- 옵션 값:
- RangeAssignor: 파티션을 범위별로 할당한다.
- RoundRobinAssignor: 파티션을 라운드로빈 방식으로 할당한다.
- StickyAssignor: 동일한 컨슈머에게 가능한 한 동일한 파티션을 유지한다.
- CooperativeStickyAssignor: 점진적 리밸런싱을 지원하여 파티션 이동을 최소화한다.
- 기본값: RangeAssignor
사용 예제
"my-topic"이라는 토픽에서 메시지를 소비하는 예제다.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}4. Admin API
Admin API는 카프카 클러스터와 관련된 관리 작업을 수행하는 데 사용된다. 이 API를 통해 토픽 생성, 삭제, 설정 변경 등 관리 작업을 프로그래밍적으로 수행할 수 있다.
주요 기능
- 토픽 생성/삭제: Admin API를 사용하여 토픽을 생성하거나 삭제할 수 있다.
- 설정 변경: 토픽, 브로커 등의 설정을 동적으로 변경할 수 있다.
- ACL 관리: 카프카 클러스터에 대한 접근 제어 목록(ACL)을 관리할 수 있다.
- 클러스터 정보 조회: 클러스터의 메타데이터를 조회하여 브로커, 토픽, 파티션 정보 등을 확인할 수 있다.
4.3 사용 예제
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
AdminClient admin = AdminClient.create(props);
NewTopic newTopic = new NewTopic("my-new-topic", 1, (short) 1);
admin.createTopics(Collections.singletonList(newTopic));
admin.close();'기타 > apache kafka' 카테고리의 다른 글
| Kafka MirrorMaker 2 (0) | 2024.08.17 |
|---|---|
| 카프카 커넥트 (1) | 2024.08.17 |
| 카프카 스트림즈 (0) | 2024.08.11 |
| 아파치 카프카란? (1) | 2024.08.05 |
| Apache Kafka의 탄생 배경과 왜 사용해야하는가? (0) | 2024.08.03 |


