
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 기술블로그
- ES
- kotlin
- JPA
- Elasticsearch
- 개발
- Baekjoon
- 클린코드
- framework
- 그리디알고리즘
- 자바
- 애자일기법
- 코딩테스트
- API
- Spring
- database
- AI
- 데이터베이스
- 프레임워크
- 코드
- 개발자
- 그리디
- 백준
- spring boot
- 알고리즘
- 코딩
- Java
- 스프링
- cleancode
- 엘라스틱서치
Archives
- Today
- Total
튼튼발자 개발 성장기🏋️
AWS AppSync with DynamoDB 본문
반응형
AWS에서 2018년 정식 출시한 AppSync를 사용하여 DynamoDB에서 데이터를 조회해본다.
GraphQL을 기반으로한 AppSync는 [그림 1]과 같이 AWS Lambda, DynamoDB, Elasticsesarch, Aurora 또는 HTTP를 이용해 브로드캐스팅하여 원본 데이터를 가지고 손쉽게 api를 제공해줄 수 있다. 이를 이용하여 운영 중에도 신규 api가 추가되거나 기존 api의 spec이 변경되거나 신규 앤드포인트가 생겨도 큰 변화 없이 간편하게 api를 제공하기 위함이다.

AppSync API 생성
step 1. AppSync > APIs 우측 상단에 API 생성 버튼 클릭

step 2. API type 선택: GrapgQL APIs, Design from scratch
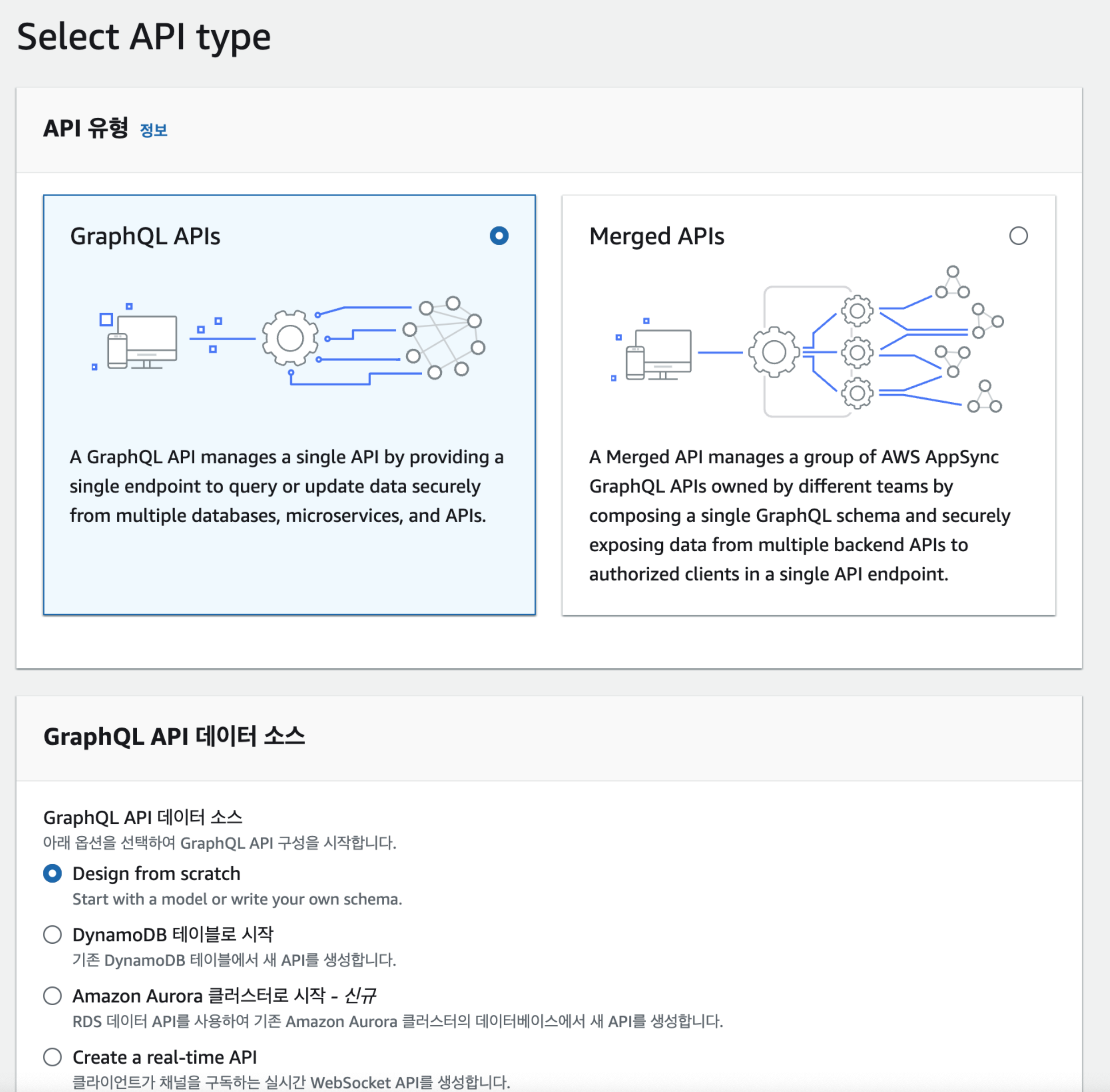
- [그림 3]와 같이 API의 유형과 데이터 소스를 선택할 수 있다.
- GraphQL APIs: 단일 백엔드 API에서 데이터를 쿼리하거나 업데이트한다.
- Merged APIs: 여러 백엔드 API에서 클라이언트에 데이터를 전달하고 다수의 GraphQL API의 그룹을 관리한다.
- DynamoDB를 사용하기위해 DynamoDB data source를 선택해야하나 DynamoDB의 테이블을 먼저 생성하는 것이 선행되어야한다. 지금은 Design from scratch를 선택한다.
step 3. API 세부 정보 지정
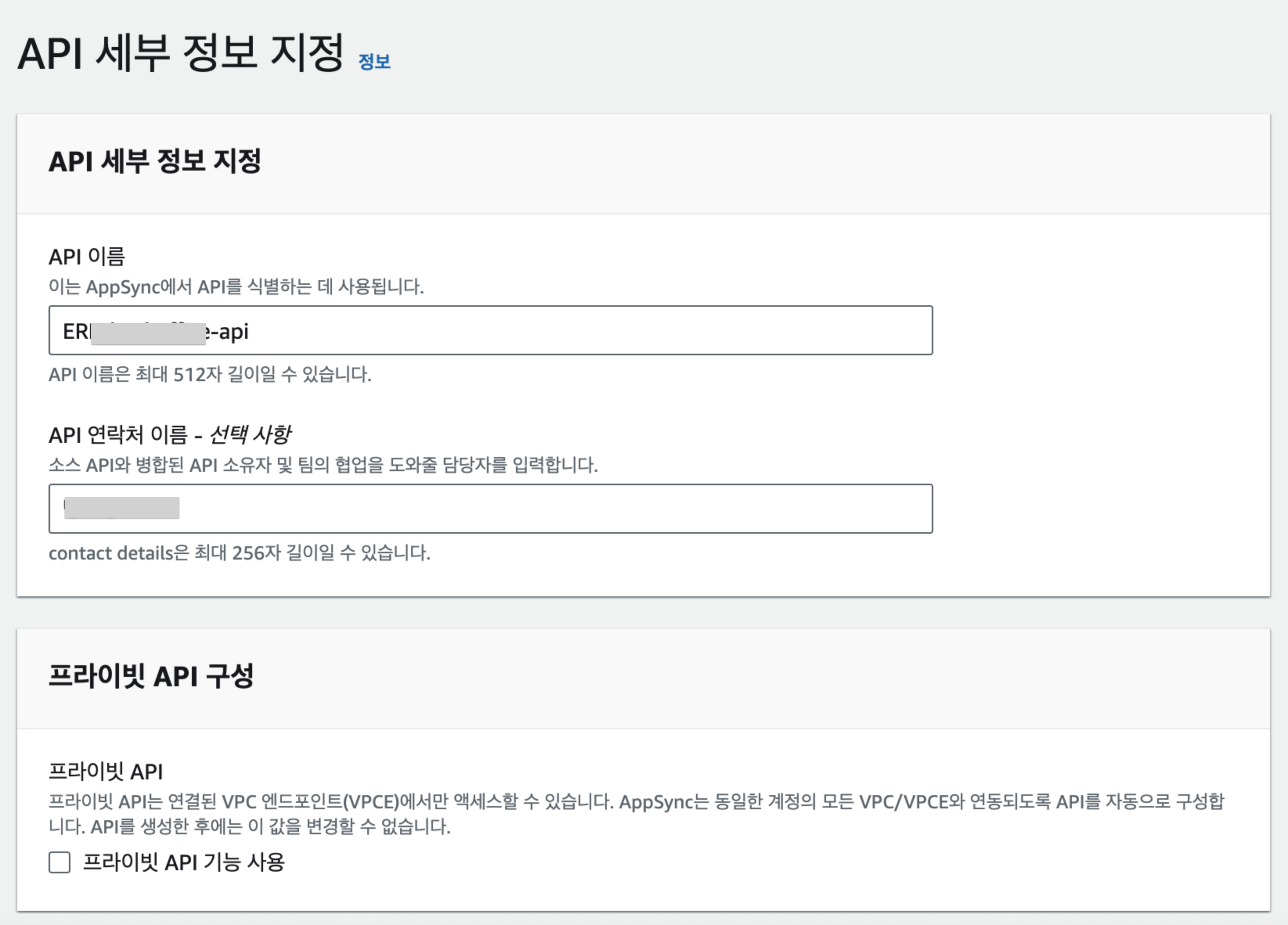
- api명과 프라이빗 api 구성을 선택한다.
- 프라이빗 api의 경우에는 AWS VPC 내에서만 사용할 api라면 선택해준다. 그러면 기본적으로 외부 네트워크 망에서는 통신할 수 없다.
- 자세한 내용 참고: https://aws.amazon.com/ko/blogs/mobile/architecture-patterns-for-aws-appsync-private-apis/
- nlb를 사용해서 vpc link를 통해 연결시키는 것을 알 수 있다.
step 4. GraphQL 리소스 지정

- GraphQL 리소스 지정을 위해 DynamoDB의 테이블을 선택해야하나, DynamoDB 테이블 생성이 선행되어야하므로 밑에서 생성하여 지정하도록한다. 지금은 “나중에 GraphQL 리소스를 생성”을 선택한다.
step 5. schema 생성
- 스키마를 아래와같이 작성한다.
- Corp type은 java에서의 class라고 생각하면 편하다. Corp라는 모델이다.
- Mutation type은 데이터를 변경하기 위한 작업들을 선언한다. 여기서는 addCorp(…)만 선언했다.
- Query type은 쿼리를 이용해 데이터를 조회하기 위한 작업들을 선언한다.
- schema는 Query와 Mutation이라는 스키마를 선언한다.
- 느낌표(!)는 not null을 의미한다.
- 우측 상단에 스키마 저장 버튼을 클릭한다.
type Corp {
id: ID!
corpNo: String
name: String
phoneNumber: String
author: String
title: String
content: String
url: String
ups: Int!
downs: Int!
version: Int!
}
type Mutation {
addCorp(corpNo: String!, name: String, phoneNumber: String): Corp!
}
type Query {
getCorpById(id: ID!): Corp
}
schema {
query: Query
mutation: Mutation
}atep 6. 리소스 생성
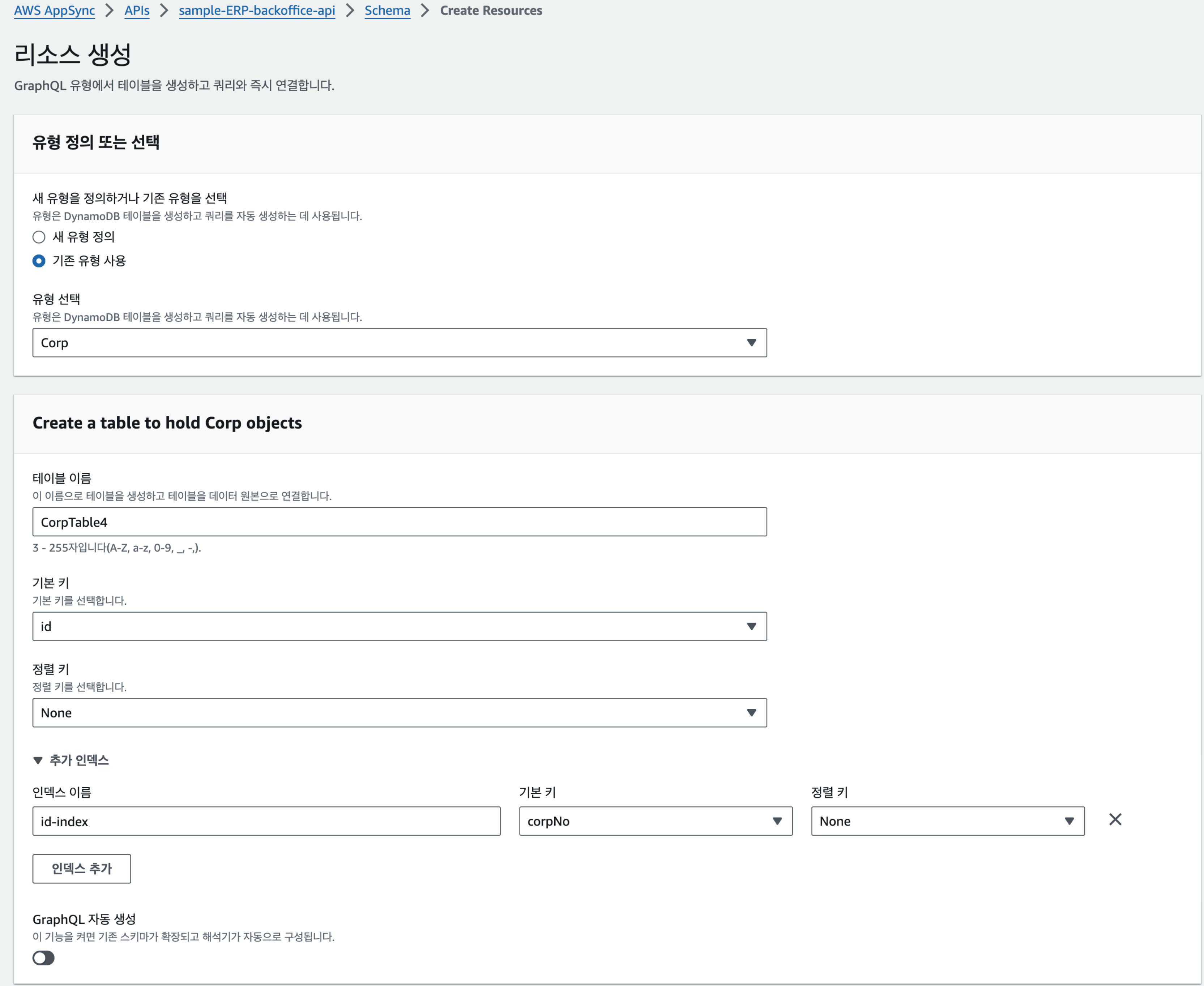

- 우측 상단에 리소스 생성을 클릭한다.
- 리소스는 우리가 step5에서 유형을 만들었으므로 “기존 유형 사용”을 선택하고 “유형 선택”에서 우리가 만든 Corp Type을 선택한다.
- 생성할 테이블명과 기본 키, 정렬 키를 선택하되, 기본적으로 정렬이 필요없다면 None을 선택한다.
- 인덱스 추가 버튼을 클릭하여 인덱스를 생성한다.
- GraphQL은 직접 작성할 예정이기 때문에 자동 생성하지 않는다.
- [그림 7]과 같이 DynamoDB > 테이블에서 테이블이 생성되었는지 확인한다.
step 7. 해석기 연결

우측 해석기 지면에서 해석기를 연결한다.
- 우리가 만든 Mutation addCorp(…)에 대한 해석기를 연결한다.
- 단일 데이터 소스에 저장/조회만 할 것이기 때문에 “단위 해석기”를 선택한다.
- 우리가 만든 데이터 원본을 선택한다.
- 캐싱은 과금이 되니 주의한다. 캐시를 사용하려면 활성화한다.
- 강화 모니터링은 과금이 되니 주의한다. CloudWatch를 통해 모니터링을 할 수 있는 기능인 듯하다.
- 우측 하단의 생성을 클릭한다.
- 해석기 코드를 아래와같이 입력한다.
import { util } from '@aws-appsync/utils' import * as ddb from '@aws-appsync/utils/dynamodb' export function request(ctx) { const item = { ...ctx.arguments, ups: 1, downs: 0, version: 1 } const key = { id: ctx.args.id ?? util.autoId() } return ddb.put({ key, item }) } export function response(ctx) { return ctx.result }- util.autoId() 함수는 aws-appsync/utils에서 제공해주는 랜덤 id 생성기이다. (UUID 랜덩 생성기)
- 우측 상단에 저장을 클릭한다.
- 마찬가지로 Query 타입에 해당하는 작업에 대해서 해석기를 연결한다.
- Query에 연결되는 해석기 코드는 아래와같이 작성한다.
-
import * as ddb from '@aws-appsync/utils/dynamodb' export function request(ctx) { return ddb.get({ key: { id: ctx.args.id } }) } export const response = (ctx) => ctx.result
step 8. 쿼리 작성
- 좌측에 쿼리 탭으로 진입한다.
- 아래와 같이 쿼리를 작성한다.
-
mutation addCorp { addCorp(corpNo: "123", name: "가보자고", phoneNumber: "010-8888-0000") { id corpNo name phoneNumber author } } query getCorpById { getCorpById(id: "2aeb9ed5-b7ef-4e1c-b539-88f4dd149b80") { id corpNo name phoneNumber author url ups downs } } - addCorp(…)를 실행하는 mutation을 선언하여 연결된 해석기를 실행한다.
- corpNo: 123, name: 가보자고, phoneNumber: 010-8888-0000이고 나머지는 default 값을 사용하여 insert 하겠다는 의미다.
- insert된 Object인 Corp 모델을 리턴을 받는데, 여기서 어떤 컬럼들을 받을지를 정의한다.
- 위 예시에는 Corp model의 id, corpNo, name, phoneNumber, author만 전달받는다.
- 실제로는 Corp type을 통채로 주지만 어떤 컬럼들을 사용할지 정의하는 것이다. (필요에 따라 유연하게 설정이 가능하다는 장점)
- getCorpById(…)룰 실행하는 query를 선언하여 연결된 해석기를 실행한다.
- id: 2aeb9ed5-b7ef-4e1c-b539-88f4dd149b80인 row를 조회한다.
- 조회된 Object인 Corp 모델을 리턴을 받는데, 여기서 어떤 컬럼들을 받을지를 정의한다.
- 위 예시에는 id, corpNo, name, phoneNumber, author, url, ups, downs만 전달받는다.
- 눈치 챘겠지만, 저장, 조회 모두 리턴되는 Object의 필요한 데이터만 받을 수 있게 손쉽게 작업이 가능하다.
-
step 9. 쿼리 실행

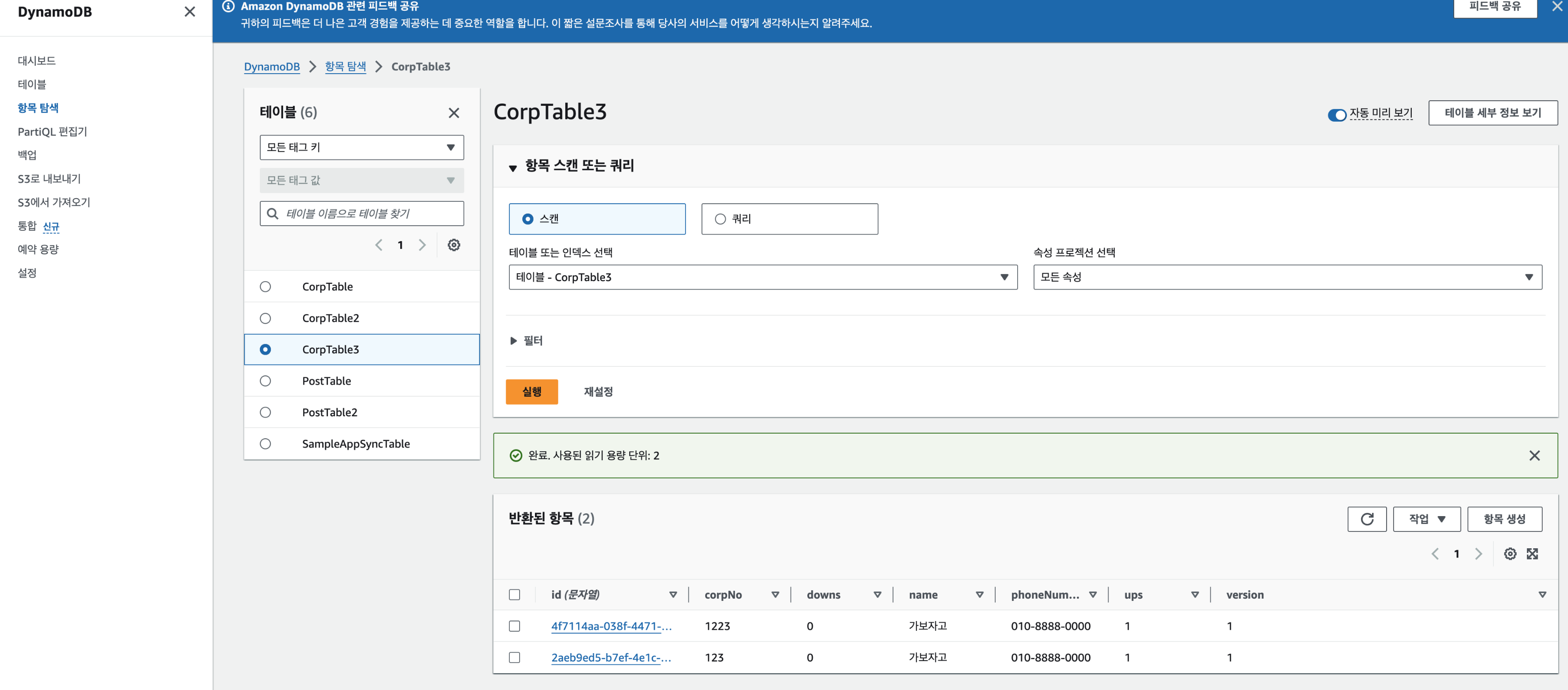
- 실행 버튼을 클릭하고 원하는 쿼리를 실행한다. 일단 addCorp(…)를 실행하여 데이터를 넣어본다.
- 결과는 우측에 노출된다.
- getCorpById(…)도 실행해보면 default 값으로 저장된 다른 컬럼들도 확인 할 수 있다.
- 실제 DynamoDB의 테이블을 보면 저장된 것을 확인해볼 수 있다.
참고 문서
반응형
'기타 > AWS Tech' 카테고리의 다른 글
| AWS MSK 벤치마킹 (0) | 2025.11.07 |
|---|---|
| AWS AppSync with OpenSearch (1) | 2024.03.29 |
| AWS AppSync 알아보기 (1) | 2024.03.18 |
'기타/AWS Tech' Related Articles
more

