
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- kotlin
- Elasticsearch
- 코드
- ES
- 코딩
- spring boot
- 자바
- framework
- 스프링
- 개발
- API
- 코딩테스트
- 엘라스틱서치
- 그리디알고리즘
- 백준
- 개발자
- Spring
- 프레임워크
- 알고리즘
- Baekjoon
- AI
- 데이터베이스
- 애자일기법
- cleancode
- 클린코드
- database
- Java
- 그리디
- 기술블로그
- JPA
- Today
- Total
튼튼발자 개발 성장기🏋️
데이터 검색: 검색 api 본문
문장은 색인 시점에 텀으로 분해되고 검색 시 이 텀을 일치시켜야 검색이 가능해진다. [그림 1]은 색인 시점과 검색 시점의 기본적인 동작 과정을 표현한다.

엘라스틱서치는 색인 시점에 Analyzer를 통해 분석된 텀을 Term, 출현빈도, 문서번호와 같이 역색인 구조를 만들어 내부적으로 저장한다. 검색 시점에는 Keyword타입과 같은 분석이 불가능한 데이터와 Text타입과 같은 분석이 가능한 데이터를 구분해서 분석이 가능할 경우 분석기를 이용해 분석을 수행한다. 이를 통해 검색 시점에도 텀을 얻을 수 있으며 해당 텀으로 역색인 구조를 이용해 문서를 찾고 이를 통해 스코어 계산으로 결과를 제공한다.
검색 질의 표현 방식
엘라스틱서치에서 제공하는 검색 api는 질의(Query)를 기반으로 동작한다. 검색 질의에는 검색하고자 하는 각종 조건들을 명시할 수 있으며 동일한 조건을 다음과 같은 두 가지 방식으로 표현할 수 있다.
- URI 검색: 루씬에서 사용하던 전통적인 방식
- Request Body 검색: RESTful api를 이용해 Request Body에 조건을 표기하는 방법
URI 검색
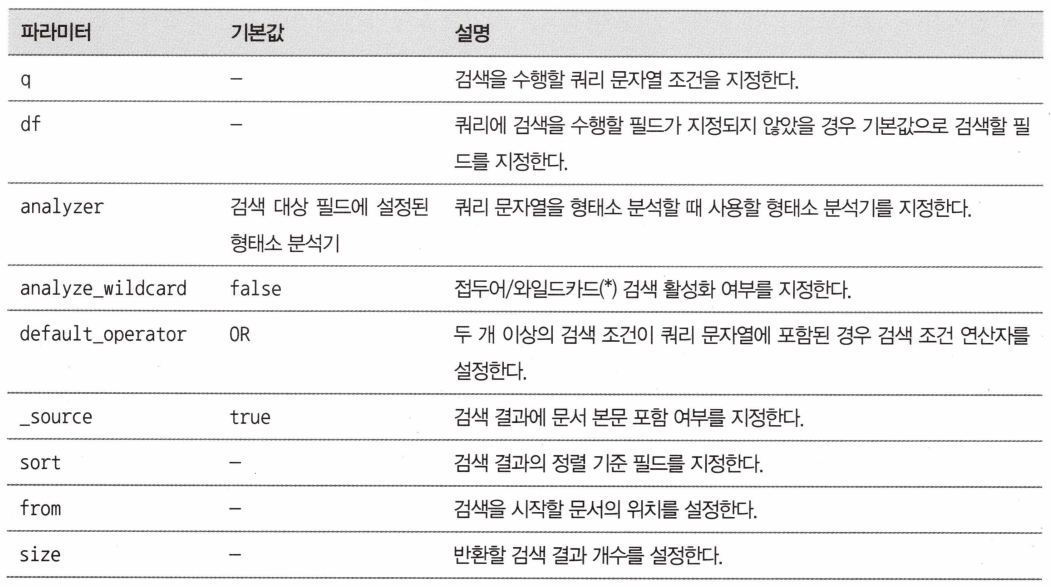
HTTP GET 요청을 활용하는 방식으로 query parameter를 사용하는 방식이다. URL에 검색할 칼럼과 검색어를 직접 지정하여 검색을 수행한다. 파라미터의 표현적 한계로 복잡한 질의를 작성하는 것은 불가능하다. 또한 엘라스틱서치에서 제공하는 모든 검색 옵션을 사용할 수 없다. 하지만 웹브라우저를 이용해 빠르게 테스트할 수 있다는 장점은 있다. URI 검색에서 자주 사용되는 파라미터는 [표 1]과 같다.
POST movie_search/_search?q=movieNmEn:* AND prdtYear:2017&analyze_wildcard=true&from=0&size=5&sort =_score:desc,movieCd: asc&_source_includes-movieCd, movieNm, mvoieNmEn, typeNm
q=movieNmEn:* AND prdtYear:2017& ===> 필드에 대한 쿼리 조건
analyze_wildcard=true& ===> 와일드카드 옵션 활성화
from=0& ===> 페이징을 위한 시작값 설정
size=5& ===> 페이징을 위한 사이즈 설정
sort =_score:desc,movieCd: asc& ===> 결과 정렬
_source_includes-movieCd, movieNm, mvoieNmEn, typeNm ===> 포함할 _source 필드명
Request Body 검색
HTTP 요청 시 Body에 검색할 칼럼과 검색어를 json 형태로 표현해서 전달하는 방식이다. 엘라스틱서치는 효율적으로 표현하기위해 QueryDSL이라는 특별한 문법을 지원한다.
POST movie_search/_search
{
"query": {
"query_string": {
"default_field": "movieNmEn",
"query": "movieNmEn:* OR prdtYear:2017"
}
},
"from": 0,
"size": 5,
"sort": [
{
"_score": {
"order": "desc"
},
"movieCd": {
"order": "asc"
}
}
],
"_source": [
"movieCd",
"movieNm",
"mvoieNmEn",
"typeNm"
]
}
Query DSL 이해하기
Query DSL을 이용해서 질의를 하면 여러 개의 질의를 조합하거나 질의 결과에 대해 다시 검색을 수행하는 등 기존의 URI 검색보다 강력한 검색이 가능하다.
Query DSL 쿼리의 구조
Query DSL로 쿼리를 작성하려면 미리 정의된 문법에 따라 json 구조를 작성해야한다. 기본적인 요청을 위한 json 구조는 아래와 같다.
{
"size": # 리턴받는 결과의 개수를 지정한다. 기본 값은 10
"from": # 몇 번째 문서부터 가지고 올지를 지정한다. 기본 값은 0
"timeout": # 검색을 요청해서 결과를 받는 데까지 걸리는 시간. 기본 값은 무한대
"_source" : {} # 검색시 필요한 필드만 출력하고 싶을 때 사용한다.
"query": {} # 검색 조건문이 들어가는 공간이다.
"aggs": {} # 통계 및 집계 데이터를 사용할 때 사용하는 공간이다.
"sort" : {} # 문서 결과를 어떻게 출력할지에 대한 조건을 사용하는 공간이다.
}
엘라스틱서치로 쿼리가 요청되면 해당 쿼리를 파싱해서 문법에 맞는 요청인지 검사한다. 파싱에 성공하면 해당 쿼리를 기반으로 검색을 수행하고 결과를 json 형식으로 제공한다.
{
"took": # 쿼리를 실행한 시간
"timed_out": # 초과된 쿼리 시간
"_shards": {
"total": # 쿼리를 요청한 전체 샤드의 개수
"successful": # 검색 요청에 성공적으로 응답한 샤드의 개수
"failed": # 검색 요청에 실패한 샤드의 개수
},
"hits": {
"total": # 검색어에 매칭된 문서의 전체 개수
"max_score": # 일치하는 문서의 스코어 값 중 가장 높은 값
"hits": [] # 각 문서 정보와 스코어 값
}
}
Query DSL 쿼리와 필터
Query DSL을 이용해서 검색 질의를 작성할 때 조금만 조건이 복잡해지더라도 여러 개의 작은 질의를 조합해서 사용해야한다. 이때 작성되는 작은 질의들을 두 가지의 형태로 나눠서 생각해볼 수 있다. 실제 분석기에 의한 전문 분석이 필요한 경우와 단순히 'yes/no'로 판단할 수 있는 조건 검색의 경우다. 엘라스틱서치에서는 전자를 쿼리 컨텍스트라고하고 후자를 필터 컨텍스트라고 부른다.

Query DSL의 주요 파라미터
Multi Index 검색
기본적으로 모든 검색 요청은 Multi Index 및 Multi Type 검색이 가능하다. 이러한 특성으로 다수의 인덱스를 검색할 때 한 번의 요청으로 검색 결과를 얻을 수 있다. 검색 요청시 콤마(,)를 이용해 다수의 인덱스명을 입력할 수 있다.
POST movie_search, movie_auto/_search
{
"query": {
"term": {
"repGenreNm":"다큐멘터리"
}
}
}
POST /log-2019-*/_search # 와일드카드 사용 예
쿼리 결과 페이징
페이징을 구현하기 위해서는 제공되는 문서의 시작을 나타내는 from, 문서의 개수를 나타내는 size 두 가지 파라미터를 사용해야한다. 엘라스틱서치는 DB와 다르게 페이징된 해당 문서만 선택적으로 가져오는 것이 아니라 모든 데이터를 읽게된다. 아래 예제에서 5건씩 페이징한 검색 결과의 두 번째 페이지를 요청하더라도 총 10건을 읽는다는 이야기다.
#첫 번째 페이지 요청
POST movie_search/_search
{
"from": 0,
"size": 5,
"query": {
"term": {
"repNationNm":"한국"
}
}
}
#두 번째 페이지 요청
POST movie_search/_search
{
"from": 5,
"size": 5,
"query": {
"term": {
"repNationNm":"한국"
}
}
}
쿼리 결과 정렬
스코어 값으로 정렬하는 것이 아니라 필드의 이름이나 가격, 날짜 등을 기준으로 재정렬하고 싶은 경우가 있다. 이럴 때 sort 파라미터를 사용할 수 있다. 결과 중 스코어 값이 같은 경우에는 두 번째 정렬을 사용해 문서의 순위도 변경할 수 있다.
POST movie_search/_search
{
"query": {
"term": {
"repNationNm":"한국"
}
},
"sort": {
"prdtYear": {
"order": "asc"
}
}
}
POST movie_search/_search
{
"query": {
"term": {
"repNationNm":"한국"
}
},
"sort":{
"prdtYear": {
"order": "asc"
},
"_score": {
"order": "desc"
}
}
}
_source 필드 필터링
실제 데이터는 _source 항목 아래존재하며 무서 내부에 존재하는 각 필드가 모두 결과로 제공된다.
{
"hits" : {
"total": 1,
"max_score": 0.6099695,
"hits" : [{
"_index": "movie_search",
"_type" : "_doc",
"_id": "2",
"_score": 0.6099695,
"_source" : {
"movieCd": "20174244",
"movieNm":"버블 패밀리",
"movieNmEn": "Family in the Bubble"
}
}]
}
}
범위 검색
숫자나 날짜 데이터의 경우에는 값을 지정하지 않고 범위를 지정하여 질의할 수 있다.
POST movie_search/_search
{
"query": {
"range": {
"prdtYear": {
"gte": "2016",
"lte": "2017"
}
}
}
}
operator 설정
일전에도 언급한 바 있지만 엘라스틱서치 검색 시 문장이 들어올 경우 기본적으로 OR 연산으로 동작한다. Query DSL에서는 operator 파라미터를 통해 연산자를 명시적으로 지정하는 것이 가능하다.
POST movie_search/_search
{
"query": {
"match": {
"movieNm": {
"query": "자전차왕 엄복동"
"operator": "and"
}
}
}
}
minimum_should_match 설정
OR 연산을 수행할 경우 사용할 수 있는 옵션이 있다. 일반적으로 OR 연산을 수행할 경우 검색 결과가 많이 나올 수 있는데, 이런 경우 텀의 개수가 몇 개 이상 매칭될 때만 검색 결과로 나오게 할 수 있는데 이 때 사용하는 것이 minimum_should_match 파라미터이다. minimum_should_match 파라미터를 사용하면 AND 연산과 비슷한 효과를 낼 수 있다.
POST movie_search/_search
{
"query": {
"match": {
"movieNm": {
"query":"자전차왕 엄복동"
"minimum should_match": 2
}
}
}
}
fuzziness 설정
단순히 같은 값을 찾는 Match Query를 유사한 값을 찾는 Fuzzy Query로 변경할 수 있다. 이는 레벤슈타인 편집 거리 알고리즘을 기반으로 문서의 필드 값을 여러 번 변경하는 방식으로 동작한다. 유사한 검색 결과를 찾기 위해 허용 범위의 텀으로 변경해가며 문서를 찾아 결과로 출력한다. 오차 범위로 0, 1, 2, AUTO로 총 4가지 값을 사용할 수 있다.
POST movie_search/_search
{
"query": {
"match":{
"movieNmEn": {
"query": "Fli High",
"fuzziness": 1
}
}
}
}
boost 설정
관련성이 높은 필드나 키워드에 가중치를 더 줄 수 있게 해줄 수 있다. 예를 들어 영화 데이터의 경우 한글 영화 제목과 영문 영화 제목으로 두 가지 제목 필드를 제공하고 있다. 이 때 한글 영화 제목에 좀 더 가중치를 부여해서 검색 결과를 좀 더 상위로 올리고 싶을 때 사용한다.
POST movie_search/_search
{
"query":{
"multi_match": {
"query": "Fly",
"fields": ["movieNm^3", "movieNmEn"]
}
}
}'Reading > 엘라스틱서치 실무 가이드' 카테고리의 다른 글
| 데이터 검색: Query DSL 주요 쿼리 (2) | 2023.12.14 |
|---|---|
| Document API 이해하기 (0) | 2023.12.13 |
| 데이터 모델링: 전처리 필터 (0) | 2023.12.13 |
| 데이터 모델링: 분석기 (1) | 2023.12.10 |
| 데이터 모델링: 데이터 타입 (1) | 2023.12.09 |

