
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 그리디
- 코딩
- 그리디알고리즘
- 코드
- JPA
- Java
- 스프링
- AI
- 개발
- 백준
- framework
- spring boot
- cleancode
- Elasticsearch
- API
- 개발자
- 코딩테스트
- ES
- 자바
- database
- 애자일기법
- Spring
- 엘라스틱서치
- 알고리즘
- kotlin
- Baekjoon
- 데이터베이스
- 프레임워크
- 클린코드
- 기술블로그
- Today
- Total
튼튼발자 개발 성장기🏋️
데이터 모델링: 분석기 본문
텍스트 분석 개요
엘라스틱서치는 루씬을 기반으로 구축된 텍스트 기반 검색엔진이다. 루씬은 내부적으로 다양한 분석기를 제공하는데 엘라스틱서치는 루씬이 제공하는 분석기를 그대로 활용한다. 그렇기 때문에 이 분석기를 어떻게 동작하는지 이해하고 구성하는 것이 중요하다.
"우리나라가 좋은나라, 대한민국 화이팅" 문장이 있다고 가정해보자. 이 문장을 검색하기 위해 "대한민국"이라고 입력한다면 "우리나라"라는 단어가 존재하지 않기 때문에 검색이 되지않는다.
엘라스틱서치는 문서를 색인하기 전에 해당 문서의 필드 타입이 무엇인지 확인하고 텍스트 타입이면 분석기를 통해 이를 분석한다. 텍스트가 분석되면 개별 텀으로 나뉘어 형태소 형태로 분석이 수행된다. 해당 형태소는 특정 원칙에 의해 필터링되어 단어가 삭제되거나 추가/수정되고 최종적으로 역색인된다. 이러한 텍스트 분석은 언어별로 조금씩 다르게 동작하기 때문에 언어별로 분석기를 제공한다. 만약 원하는 분석기가 없다면 직접 개발하거나 Custom Analyzer를 설치해서 사용할 수도 있다. 아래와 같이 토큰은 4부분으로 나뉘는 것을 볼 수 있다.
POST _analyze
{
"analyzer" : "standard",
"text" : "우리나라가 좋은나라, 대한민국 화이팅"
}
# result
{
"tokens": [
{
"token": "우리나라가",
"start_offset": 0,
"end_offset": 5,
"type": "<HANGUL>",
"position": 0
},
{
"token": "좋은나라",
"start_offset": 6,
"end_offset": 10,
"type": "<HANGUL>",
"position": 1
},
{
"token": "대한민국",
"start_offset": 12,
"end_offset": 16,
"type": "<HANGUL>",
"position": 2
},
{
"token": "화이팅",
"start_offset": 17,
"end_offset": 20,
"type": "<HANGUL>",
"position": 3
}
]
}
역색인 구조
어떤 책을 읽을 때 특정 단어가 등장하는 페이지가 몇번 페이지인지 찾기 위해 가장 마지막 페이지를 찾아보곤한다. 그로써 빠르게 찾아 볼 수 있게한다. 루씬의 역색인이란 이러한 것을 이야기한다.
역색인 구조를 간단하게 정리하자면 아래와 같다.
- 모든 문서가 가지는 단어의 고유 단어 목록
- 해당 단어가 어떤 문서에 속해있는지에 대한 정보
- 전체 문서에 각 단어가 몇 개 들어있는지에 대한 정보
- 하나의 문서에 각 단어가 몇 번씩 출현했는지에 대한 빈도
분석기의 구조
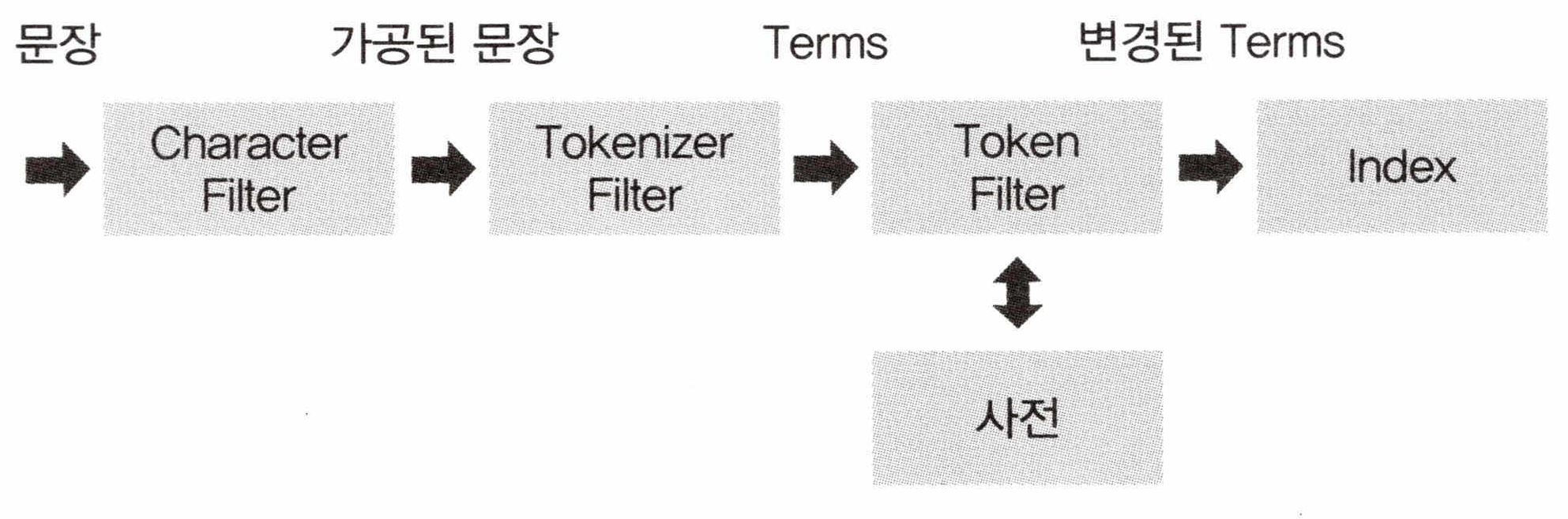
분석기는 아래와 같은 프로세스로 동작한다.
- 문장을 특정한 규칙에 의해 수정한다.
- 수정한 문장을 개별 토큰으로 분리한다.
- 개별 토큰을 특정한 규칙에 의해 변경한다.
이 세가지 동작은 특성에 의해 각각 아래와 같은 용어로 불린다.
CHARACTER FILTER
문장을 분석하기 전에 입력 테스트에 대해 특정한 단어를 변경하거나 HTML과 같은 태그를 제거하는 역할을 하는 필터다. 해당 내용은 텍스트를 개별 토큰화하기 전의 전처리 과정이며 ReplaceAll() 메서드처럼 패턴으로 텍스트를 변경하거나 사용자가 정의한 필터를 적용할 수 있다.
TOKENIZER FILTER
분석기를 구성할 때 하나만 사용할 수 있으며 텍스트를 어떻게 나눌 것인지를 정의한다.
TOKEN FILTER
토큰화된 단어를 하나씩 필터링해서 사용자가 원하는 토큰으로 변환한다. 예를들어 영단어를 소문자로 변환하는 등의 작업을 수행한다. 여러 단계가 순차적으로 이뤄지며 순서는 어떻게 지정하느냐에 따라 검색의 질이 달라질 수 있다.
아래와 같은 문서가 있고 HTML 태그를 제거하고 소문자로 변형해서 인덱스를 저장하는 프로세스를 구성해보자.
<B>Elasticsearch</B> is cool
PUT /movie_analyzer
{
"settings": {
"index" : {
"number_of_shards": 5,
"number_of_replicas" : 1
}
},
"analysis": {
"analyzer": {
"custom_movie_analyzer": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
}
}
}html_strip으로 Character Filter를 적용했고 standard Tokenizer Filter를 정의했으며(특수문자 혹은 공백을 기준으로 텍스트 분할) lowecase로부터 Token Filter를 적용했다. 이렇게 구성한다면 [그림 2]와 같은 단계를 거쳐서 토큰이 정제될 것이다.

분석기 사용법
엘라스틱서치는 루씬에 존재하는 기본 분석기를 별도의 정의없이 사용할 수 있게 미리 정의해서 제공한다. 이러한 분석기를 사용하기 위해 엘라스틱서치는 _analyze api를 제공한다.
분석기를 이용한 분석
위 언급된 바 있는 _analyzer api는 형태소가 어떻게 분석되는지를 확인할 수 있다.
필드를 이용한 분석
인덱스를 설정할 때 분석기를 직접 설정할 수 있다. 이때 다양한 옵션과 필터를 적용해 분석기를 설정할 수 있는데 이렇게 설정한 분석기를 맵핑 설정을 통해 칼럼에 지정할 수 있다.
색인과 검색시 분석기를 각각 설정
데이터 모델링: 맵핑 api에서 언급된 바와같이 search_analyzer 맵핑 파라미터를 이용하여 색인과 검색시 서로 다른 분석기를 사용할 수 있도록할 수 있다. 인덱스를 생성할 때 색인용과 검색용 분석기를 각각 정의하고 적용하고자하는 필드에 원하는 분석기를 지정하면 된다.
PUT movie_analyzer
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"analysis": {
"analyzer":{
"movie_lower_test_analyzer":{
"type": "custom",
"tokenizer":"standard",
"filter":[
"lowercase"
]
},
"movie_stop_test_analyzer":{
"type": "custom",
"tokenizer":"standard",
"filter": [
"lowercase",
"english_stop"
}
},
"filter":{
"english_stop":{
"type": "stop",
"stopwords":"_english_"
}
}
}
}
"mappings": {
"_doc":{
"properties":{
"title": {
"type":"text",
"analyzer":"movie_stop_test_analyzer",
"search_analyzer":"movie_lower_test_analyzer"
}
}
}
}
}
}
대표적인 분석기
Standard Analyzer
분석기를 설정하지 않으면 자동으로 구성되는 기본 분석기이다. 이 분석기는 공백 혹은 특수 기호를 기준으로 토큰을 분리하고 모든 문자를 소문자로 변경하는 토큰 필터를 사용한다. 옵션은 아래와 같다.
| 파라미터 | 설명 |
| max_token_length | 최대 토큰 길이를 초과하는 토큰이 보일 경우 해당 length 간격으로 분할한다. 기본값은 255 |
| stopwords | 사전 정의된 불용어 사전을 사용한다. 기본값은 사용하지 않는다. |
| stopwords_path | 불용어가 포함된 파일을 사용할 경우의 서버의 경로로 사용한다. |
Whitespace 분석기
공백 문자영ㄹ을 기준으로 토큰을 분리하는 간단한 분석기다.
Keyword 분석기
전체 입력 문자열을 하나의 키워드처럼 처리한다. 토큰화 작업을 하지 않는다.
'Reading > 엘라스틱서치 실무 가이드' 카테고리의 다른 글
| Document API 이해하기 (0) | 2023.12.13 |
|---|---|
| 데이터 모델링: 전처리 필터 (0) | 2023.12.13 |
| 데이터 모델링: 데이터 타입 (1) | 2023.12.09 |
| 데이터 모델링: 메타 필드 (1) | 2023.12.08 |
| 데이터 모델링: 맵핑 api (2) | 2023.12.05 |