
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 그리디알고리즘
- spring boot
- 코딩
- Java
- 데이터베이스
- 코딩테스트
- 애자일기법
- Baekjoon
- 스프링
- 그리디
- API
- Elasticsearch
- 엘라스틱서치
- 개발자
- 알고리즘
- database
- 기술블로그
- framework
- 개발
- 백준
- Spring
- 클린코드
- cleancode
- 코드
- 프레임워크
- 자바
- JPA
- kotlin
- AI
- ES
- Today
- Total
튼튼발자 개발 성장기🏋️
#6 인덱스: 색인 본문
앞서 언급한 분산의 포인트는 OS 캐시 활용과 인덱스(색인) 사용 그리고 확장을 고려하여 시스템을 설계하는 것이다. (MySQL은 물론이고 RDBMS는 인덱스를 생성하고 그로 인해 빠르게 데이터를 검색할 수 있는 구조가 마련되어 있다.)
보통 신규 프로젝트를 개발하게 될 때면 테이블 스키마를 그려하고 create table 쿼리로 테이블을 생성할 수 있다. 이 부분이 큰 규모일 수록 중요한 부분이 생기는데, 스키마를 얼마나 고려했는지, 분산과 확장성을 얼마나 고려했는지에 따라서 데이터가 큰 차이로 증감할 수 있다는 것을 이전 포스팅을 통해 알게되었다. 따라서 대량의 데이터가 저장되는 테이블일 수록 래코드가 최대한 작아지도록 컴팩트하게 설계되어야 한다.
MySQL의 인덱스 경우에는 빠른 탐색을 위해 B트리에서 파생된 "B+트리"라는 데이터구조다. B트리는 각 노드가 여러 자식을 가질 수 있는 다분트리 성격과 동시에 데이터 삽입이나 삭제를 반복해도 트리 형태가 한쪽으로 치우치니 않는 평형트리 성격을 가지고 있다.
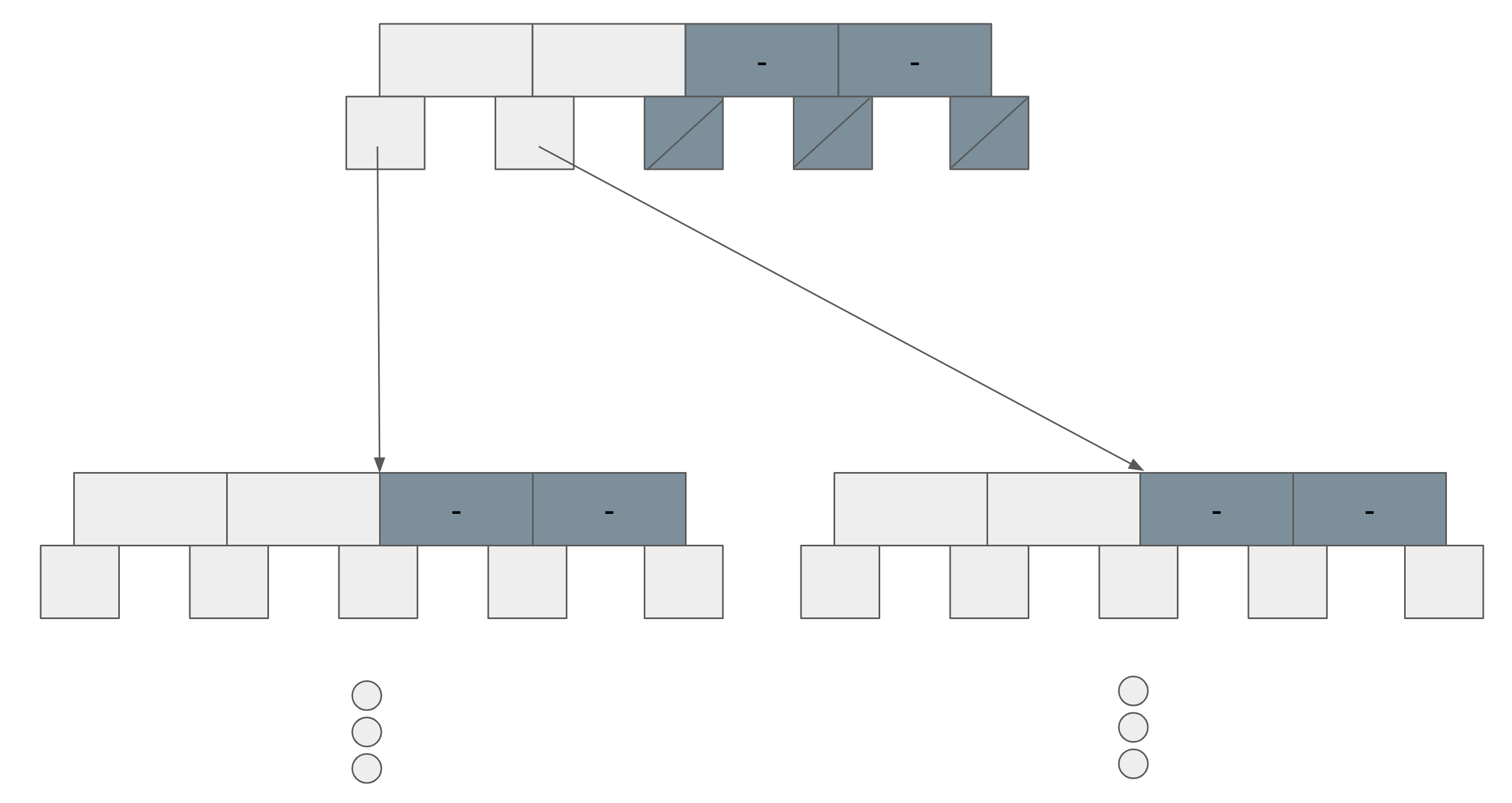
B트리에 데이터를 삽입할 때는 일정한 규칙에 따라 삽입할 필요가 있는데, 그 규칙 덕분에 검색할 때 일부 노드를 순회하는 것만으로도 자연스럽게 찾고자하는 데이터에 도달하게 된다.
찾는 값의 대소관계로 어떤 자식을 찾아가면 될지 한 번에 결정될 수 있는 규칙을 사용하는 B트리의 탐색과정은 아래와 같다.
- root에서 시작
- 각 노드에 찾고 있는 값이 저장되어 있는지 확인
- 없으면 자식을 찾아간다
[그림 1]과 같이 검색할 때 최대 높이 트리의 높이만큼의 횟수만 자식을 찾아가면 되기 때문에 빠른 탐색이 가능하다. B트리의 계산량은 O(logN)이다. (선형탐삭을 할 경우에는 O(n)) 여기서 핵심은 인덱스를 사용하면 그만큼 디스크 seek 횟수면에서도 개선이 가능하다는 뜻이기도하다.(유레카!!! 단순히 인덱스를 쓰면 빠르니까 사용했는데 왜 빠른지에 대해서는 생각해보지 않은 내 자신이 너무 작아진다....ㅋ)
※ 인덱스의 작동 여부를 확인하는 방법은 explain이라하는 명령으로 알 수 있다. 이는 실행 계획 과정과 옵티마이저 등을 함께 알아야해서 상당히 글이 길어질 것같아서 따로 포스팅할 예정
'Reading > 대규모 서비스를 지탱하는 기술' 카테고리의 다른 글
| #5 국소성과 분산 (1) | 2022.05.13 |
|---|---|
| #4 OS 캐시 (0) | 2022.05.06 |
| #3 대규모 서비스를 다루기 전 기초 지식 (0) | 2022.04.20 |
| #2 디스크와 메모리 (0) | 2022.04.15 |
| #1 왜 대규모 서비스인가? (0) | 2022.04.15 |



