
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 클린코드
- 데이터베이스
- ES
- 코드
- framework
- spring boot
- database
- cleancode
- 프레임워크
- 백준
- 알고리즘
- 자바
- Elasticsearch
- 그리디
- 개발자
- JPA
- Baekjoon
- API
- 그리디알고리즘
- 애자일프로그래밍
- 개발
- 애자일기법
- Java
- 스프링
- 코딩
- 코딩테스트
- Spring
- kotlin
- 읽기쉬운코드
- 엘라스틱서치
- Today
- Total
튼튼발자 개발 성장기🏋️
#5 국소성과 분산 본문
지금까지 캐시가 I/O에 미치는 영향에 대해서 알아 보았다. (학교에서 language를 배울 때 캐시를 전혀 알려주지 않고 컴퓨터 개론 등의 수업에서만 캐시를 간략하게 언급하고 지나갔던 기억이 난다. 정작 현업에서는 캐시를 아주 잘 사용하고 있고 꼭 필요한 부분에서 어떤 방식으로 캐시를 사용할지에 대해 명확하게 정의하여 사용한다.)
데이터 처리 시 압축해서 저장해두면 디스크 내용을 그대로 캐싱할 수 있고, 데이터의 규모보다 물리 메모리가 더 클 때 전부 캐싱할 수 있다는 사실을 알게 되었다.
그렇다고 메모리를 대규모에 따라 계속해서 늘리기만 할 수 없다. (경제적인 비용과 밸런스 등 고려) 이럴 때 "복수 서버 확장"이 필요할 수도 있다. 어느정도 성장한 기업의 서버는 대부분 이 방안을 채택하여 사용할텐데, AP 서버를 여러 개 두는 것이다. 이는 CPU 부하를 낮추고 분산시키기 위해서다. AP 서버와 별개로 DB서버의 확장은 캐시 용량 확보 혹은 효율을 높이고자할 때 사용된다.
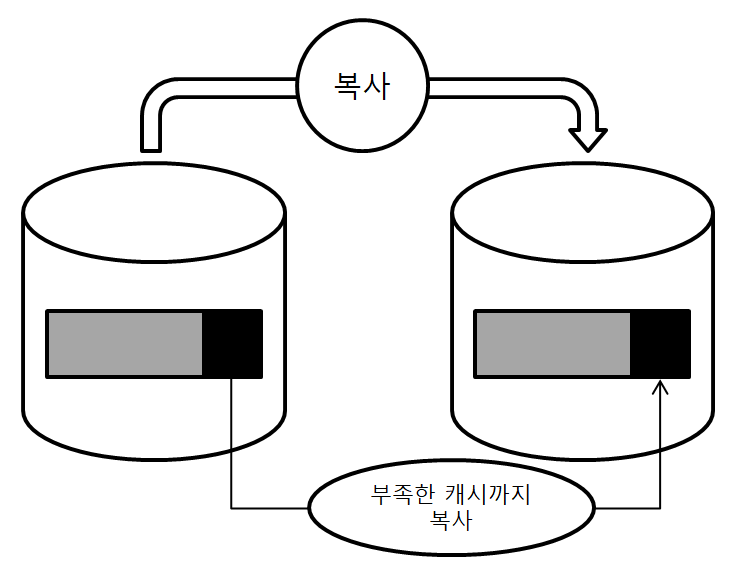
그렇다고 단순히 대수를 늘려 복사하게 된다면 [그림 1]과 같이 아무 의미 없게 되버릴 수도 있다. 캐시 용량을 늘리기위해 확장했으나, 부족한 캐시까지 동일하게 늘려버리게 된 것이다. 따라서, 부족한 캐시에 액세스한 순간에 느려지는 것은 똑같다는 이야기다.
이를 방지하기 위해서 우리는 국소성을 고려해서 분산해야한다. 즉 데이터에 대한 액세스 패턴을 고려해야한다는 것이다.
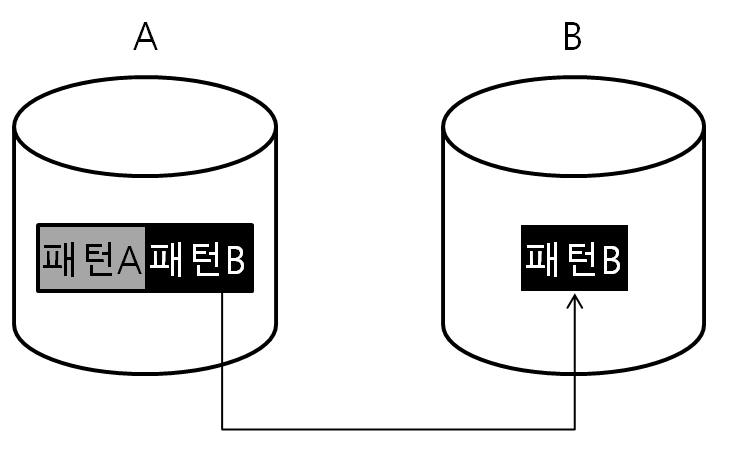
기존에는 액세스패턴A와 B 모두 A서버에 몰려 캐시 용량이 부족했다면, 인기가 많은 액세스패턴B를 B서버로 분산하도록 한다. 그렇다면 액세스패턴B는 B서버로 들어갈테고, A서버는 그 만큼의 캐시 용량을 확보할 수 있다.
결국 시스템 전체로서는 메모리에 올라간 데이터량이 늘어나게 된다.
국소성을 고려한 분산 방법론 중 파티셔닝이라는 방법도 자주 사용된다. 파티셔닝은 DB 서버를 여러 대의 서버로 분할하는 방법이다. 그 중에서 가장 간단한 것은 테이블 단위 분할이다.
서로 액세스하는 경우가 많은 테이블끼리 같은 서버에 위치시키는 것이다.
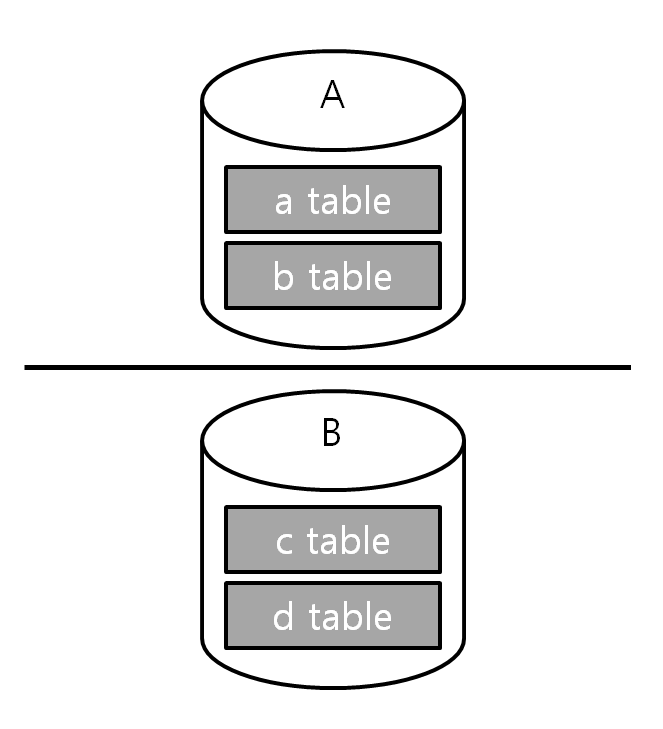
서로 액세스가 많은 a와 b 테이블은 A서버에 두고, c와 d 테이블은 B서버에 둔다. 그렇다면 a, b테이블 접근은 A서버로, c, d테이블 접근은 B서버로 application 설정이 필요할 수도 있다. (실제로 이전 직장에서 사용했었는데 처음 마주하게 되었을때 테이블에 따른 DB 서버 접근 설정을 할 줄 몰라 당황했었다...ㅋㅋㅋ)
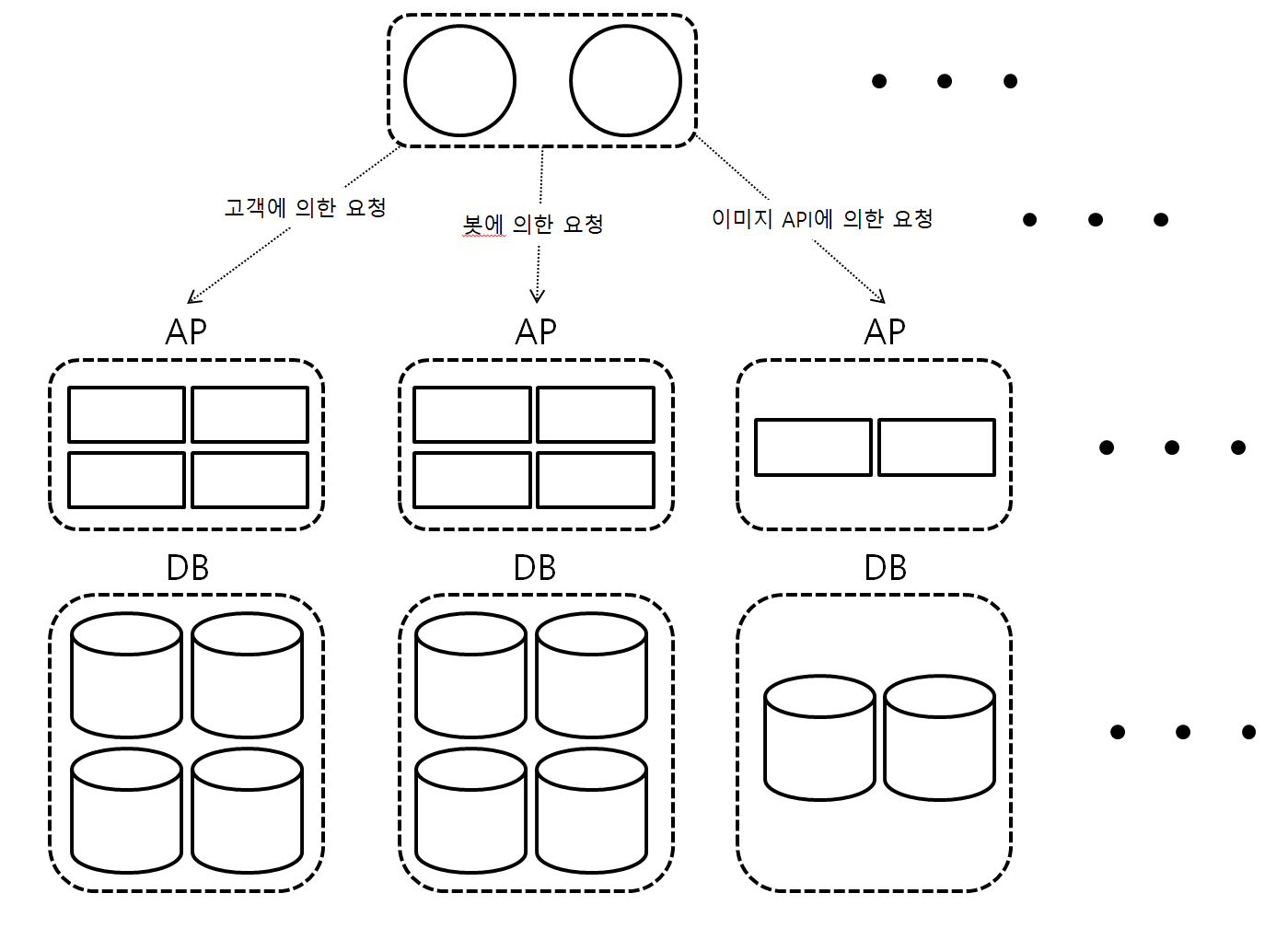
다른 방법으로는 요청 패턴을 '섬'으로 분할하는 방법이다. 예를들어 [그림 4]와 같이 HTTP의 User-Agent나 URL 등을 보고 액세스를 분배한다.
'Reading > 대규모 서비스를 지탱하는 기술' 카테고리의 다른 글
| #6 인덱스: 색인 (0) | 2022.05.25 |
|---|---|
| #4 OS 캐시 (0) | 2022.05.06 |
| #3 대규모 서비스를 다루기 전 기초 지식 (0) | 2022.04.20 |
| #1 왜 대규모 서비스인가? (0) | 2022.04.15 |


