
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Java
- 자바
- 애자일기법
- 데이터베이스
- database
- 알고리즘
- 엘라스틱서치
- 그리디
- 읽기쉬운코드
- Elasticsearch
- 클린코드
- framework
- spring boot
- kotlin
- Spring
- 스프링
- 백준
- 코딩테스트
- 애자일프로그래밍
- Baekjoon
- 개발자
- 코드
- ES
- 개발
- JPA
- cleancode
- 프레임워크
- 그리디알고리즘
- 코딩
- API
- Today
- Total
튼튼발자 개발 성장기🏋️
#1 : 기본적인 명령어 본문
협업에서는 대부분 리눅스를 기본적으로 사용할 줄 알아야 한다. 나는 대학생 시절 때 리눅스 교육과정이 없었는데 그 부분이 아직도 의아하다. 왜 없었을까.. 아무튼 이번엔 linux의 기본적인 명령어를 알아본다.
- head : 문서 내용의 앞 부분을 출력 (default 10 line)
- 가장 많이 사용하는 옵션은 -c 옵션으로, 밑에서 일정 line을 제외하고 출력하는 것.
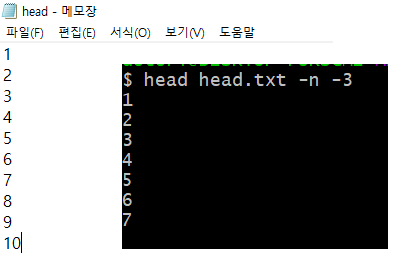
Usage: head [OPTION]... [FILE]...
Print the first 10 lines of each FILE to standard output.
With more than one FILE, precede each with a header giving the file name.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-c, --bytes=[-]NUM print the first NUM bytes of each file;
with the leading '-', print all but the last
NUM bytes of each file
-n, --lines=[-]NUM print the first NUM lines instead of the first 10;
with the leading '-', print all but the last
NUM lines of each file
-q, --quiet, --silent never print headers giving file names
-v, --verbose always print headers giving file names
-z, --zero-terminated line delimiter is NUL, not newline
--help display this help and exit
--version output version information and exit
NUM may have a multiplier suffix:
b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024,
GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y.
Binary prefixes can be used, too: KiB=K, MiB=M, and so on.
- tail : 문서의 뒷 부분을 출력
- -f 옵션을 주면 write 될 경우 계속 출력 (주로 로그를 보며 모니터링할 때 사용한다.)
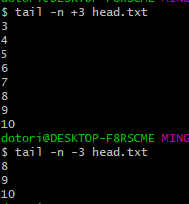
Usage: tail [OPTION]... [FILE]...
Print the last 10 lines of each FILE to standard output.
With more than one FILE, precede each with a header giving the file name.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-c, --bytes=[+]NUM output the last NUM bytes; or use -c +NUM to
output starting with byte NUM of each file
-f, --follow[={name|descriptor}]
output appended data as the file grows;
an absent option argument means 'descriptor'
-F same as --follow=name --retry
-n, --lines=[+]NUM output the last NUM lines, instead of the last 10;
or use -n +NUM to output starting with line NUM
--max-unchanged-stats=N
with --follow=name, reopen a FILE which has not
changed size after N (default 5) iterations
to see if it has been unlinked or renamed
(this is the usual case of rotated log files);
with inotify, this option is rarely useful
--pid=PID with -f, terminate after process ID, PID dies
-q, --quiet, --silent never output headers giving file names
--retry keep trying to open a file if it is inaccessible
-s, --sleep-interval=N with -f, sleep for approximately N seconds
(default 1.0) between iterations;
with inotify and --pid=P, check process P at
least once every N seconds
-v, --verbose always output headers giving file names
-z, --zero-terminated line delimiter is NUL, not newline
--help display this help and exit
--version output version information and exit
NUM may have a multiplier suffix:
b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024,
GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y.
Binary prefixes can be used, too: KiB=K, MiB=M, and so on.
- wc : Word Count의 약자로, line수, char 수, byte 수를 알 수 있다.
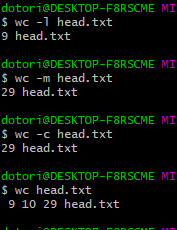
Usage: wc [OPTION]... [FILE]...
or: wc [OPTION]... --files0-from=F
Print newline, word, and byte counts for each FILE, and a total line if
more than one FILE is specified. A word is a non-zero-length sequence of
characters delimited by white space.
With no FILE, or when FILE is -, read standard input.
The options below may be used to select which counts are printed, always in
the following order: newline, word, character, byte, maximum line length.
-c, --bytes print the byte counts
-m, --chars print the character counts
-l, --lines print the newline counts
--files0-from=F read input from the files specified by
NUL-terminated names in file F;
If F is - then read names from standard input
-L, --max-line-length print the maximum display width
-w, --words print the word counts
--help display this help and exit
--version output version information and exit
- nl : 라인 수와 함께 출력
- -ba 옵션은 공백도 포함시킨다.

Usage: nl [OPTION]... [FILE]...
Write each FILE to standard output, with line numbers added.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-b, --body-numbering=STYLE use STYLE for numbering body lines
-d, --section-delimiter=CC use CC for logical page delimiters
-f, --footer-numbering=STYLE use STYLE for numbering footer lines
-h, --header-numbering=STYLE use STYLE for numbering header lines
-i, --line-increment=NUMBER line number increment at each line
-l, --join-blank-lines=NUMBER group of NUMBER empty lines counted as one
-n, --number-format=FORMAT insert line numbers according to FORMAT
-p, --no-renumber do not reset line numbers for each section
-s, --number-separator=STRING add STRING after (possible) line number
-v, --starting-line-number=NUMBER first line number for each section
-w, --number-width=NUMBER use NUMBER columns for line numbers
--help display this help and exit
--version output version information and exit
Default options are: -bt -d'\:' -fn -hn -i1 -l1 -n'rn' -s<TAB> -v1 -w6
CC are two delimiter characters used to construct logical page delimiters;
a missing second character implies ':'.
STYLE is one of:
a number all lines
t number only nonempty lines
n number no lines
pBRE number only lines that contain a match for the basic regular
expression, BRE
FORMAT is one of:
ln left justified, no leading zeros
rn right justified, no leading zeros
rz right justified, leading zeros
- uniq : 중복 제거 혹은 중복된 내용만 출력 등과같이 중복관련 command
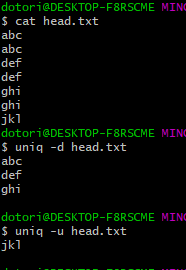
Usage: uniq [OPTION]... [INPUT [OUTPUT]]
Filter adjacent matching lines from INPUT (or standard input),
writing to OUTPUT (or standard output).
With no options, matching lines are merged to the first occurrence.
Mandatory arguments to long options are mandatory for short options too.
-c, --count prefix lines by the number of occurrences
-d, --repeated only print duplicate lines, one for each group
-D print all duplicate lines
--all-repeated[=METHOD] like -D, but allow separating groups
with an empty line;
METHOD={none(default),prepend,separate}
-f, --skip-fields=N avoid comparing the first N fields
--group[=METHOD] show all items, separating groups with an empty line;
METHOD={separate(default),prepend,append,both}
-i, --ignore-case ignore differences in case when comparing
-s, --skip-chars=N avoid comparing the first N characters
-u, --unique only print unique lines
-z, --zero-terminated line delimiter is NUL, not newline
-w, --check-chars=N compare no more than N characters in lines
--help display this help and exit
--version output version information and exit
A field is a run of blanks (usually spaces and/or TABs), then non-blank
characters. Fields are skipped before chars.
Note: 'uniq' does not detect repeated lines unless they are adjacent.
You may want to sort the input first, or use 'sort -u' without 'uniq'.
'기타 > Linux' 카테고리의 다른 글
| [centOS] 젠킨스 설치의 삽질: 그 끝은 어디인가 (2) | 2023.07.28 |
|---|
