
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 애자일기법
- 코드
- 코딩테스트
- Java
- 그리디
- 클린코드
- 자바
- 엘라스틱서치
- 개발자
- 기술블로그
- kotlin
- Elasticsearch
- database
- Spring
- 백준
- 프레임워크
- spring boot
- 코딩
- ES
- 알고리즘
- AI
- 스프링
- 그리디알고리즘
- API
- JPA
- 데이터베이스
- framework
- cleancode
- Baekjoon
- 개발
- Today
- Total
튼튼발자 개발 성장기🏋️
에이전틱 AI 디자인 패턴 본문
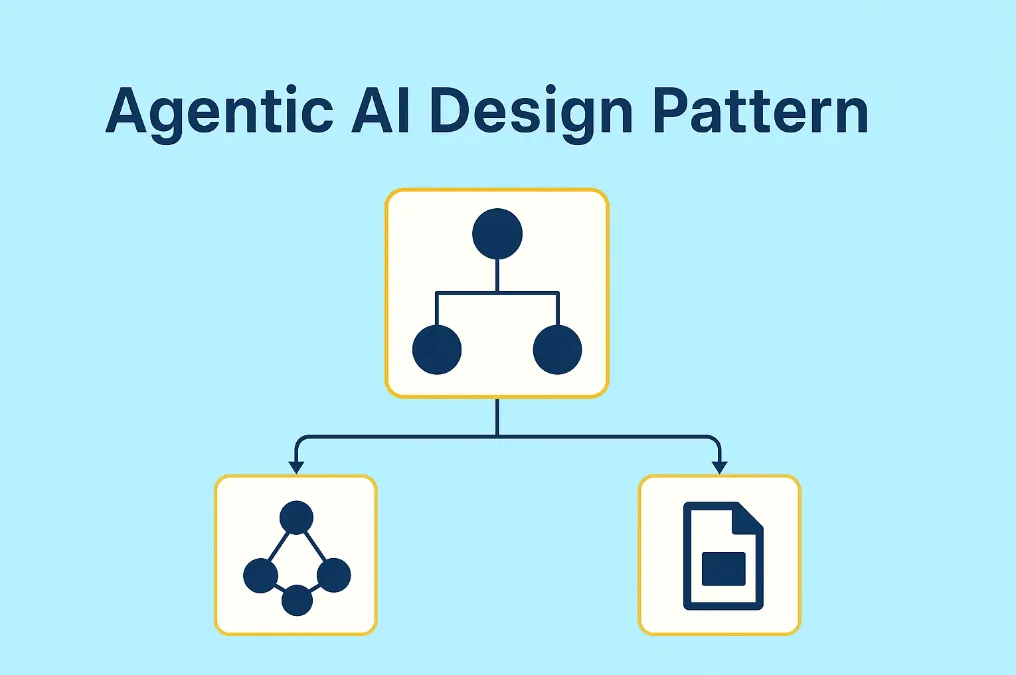
패턴 카테고리
- 싱글 에이전트 추론 패턴: CoT, ToT, GoT, Reflexion
- 멀티 에이전트 협업 패턴: MAD, 협업 프레임워크, 사회적 사고 집단
- 증강 패턴: 도구 사용, 메모리 시스템
- 고급 패턴: MCTS 기반, 자기 개선 에이전트
- 하이브리드 패턴: 적응형 추론 오케스트레이터 (권장)
구현
아래 패턴을 표준화한 오픈소스 라이브러리를 기반으로 구현합니다.
GitHub: https://github.com/balrm/agentic-patterns
설치: pip install agentic-patterns
TLDR: 디자인 패턴 선택 가이드
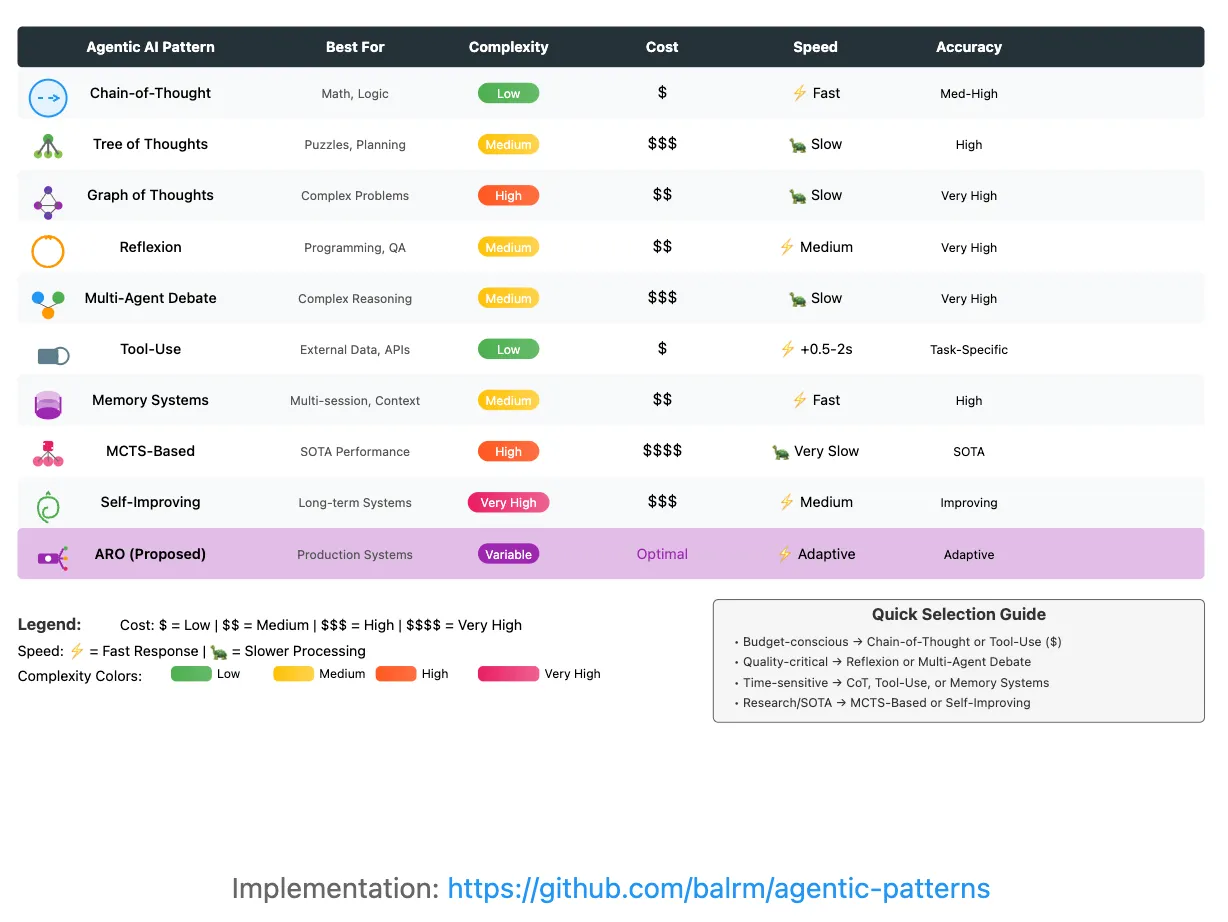
싱글 에이전트 추론 패턴
1. Chain-of-Thought (CoT)
아키텍처: 결론에 도달하기 전에 모델이 중간 추론 단계를 명시적으로 보여주는 선형 추론 체인입니다.

변형
- Few-shot CoT: 수동 예제 필요
- Zero-shot CoT: "단계별로 생각해 보자"와 같은 프롬프트 사용
- Self-Consistency CoT: 여러 추론 경로를 샘플링하고 투표
성능
- MultiArith: 17.7% → 78.7% (Zero-shot CoT) (https://arxiv.org/abs/2303.05398)
- GSM8K: Self-Consistency로 추가 17.9% 개선
- 최적의 성능을 위해 100B+ 파라미터 모델 필요
사용해야 할 때
- 수학적 추론 문제
- 다단계 논리적 추론
- 해석 가능한 추론이 필요한 작업
- 계산 예산이 제한된 경우 (단일 추론)
제한사항
- 단일 추론 경로 (Self-Consistency 변형 제외)
- 성능이 모델 크기에 크게 의존
- 오류에서 되돌아갈 수 없음
2. Tree of Thoughts (ToT)
아키텍처: 명시적인 백트래킹 기능으로 여러 추론 경로를 탐색할 수 있는 트리 구조입니다. 각 노드가 부분 솔루션을 나타내는 검색 트리를 유지합니다.
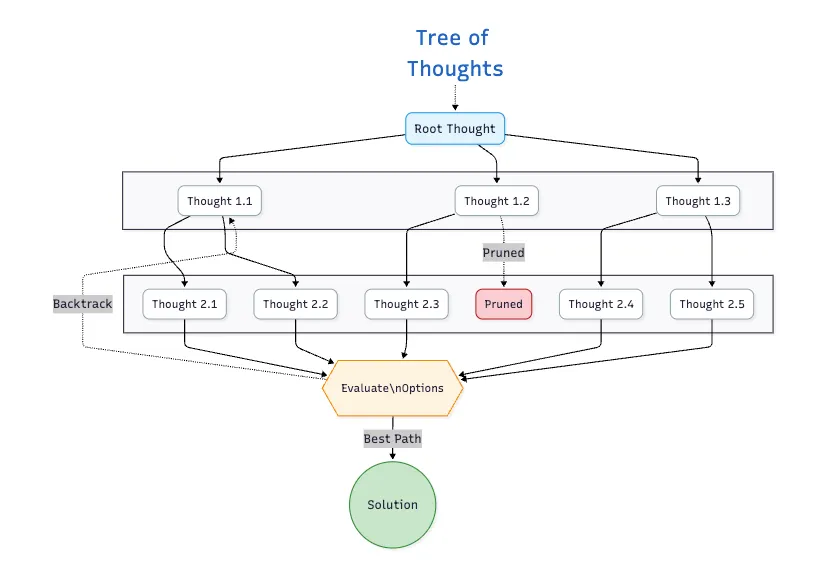
성능
- Game of 24: 74% 성공률 (CoT의 4% 대비)
- 창의적 글쓰기: 일관성에서 5.3배 개선
- 비용: b×d LLM 호출 (b=분기 계수, d=깊이)
사용해야 할 때
- 복잡한 퍼즐 및 제약 만족 문제
- 탐색이 필요한 창의적 작업 (스토리 작성, 시)
- 초기 접근법이 실패할 수 있는 문제
- 더 나은 정확도를 위해 여러 LLM 호출을 감당할 수 있는 경우
제한사항
- 높은 계산 비용 (CoT의 5–10배)
- 명시적인 평가 함수 필요
- 실시간 애플리케이션에 적합하지 않음
3. Graph of Thoughts (GoT)
아키텍처: 임의의 그래프 구조를 허용하여 ToT를 일반화합니다. 생각 병합, 정제, 분할과 같은 연산을 지원합니다. 중간 생각의 재사용을 가능하게 합니다.

성능
- ToT 대비 62% 품질 개선
- ToT 대비 31% 비용 절감
- 공유된 하위 문제가 있는 문제에 더 적합
사용해야 할 때
- 중복되는 하위 문제가 있는 문제
- 생각 집계가 도움이 되는 작업
- 여러 유효한 경로가 있는 복잡한 계획
- 생각 재사용으로 비용을 줄일 수 있는 경우
제한사항
- 복잡한 구현
- 정교한 생각 병합 로직 필요
- 간단한 문제에 대해 오버헤드 증가
4. Reflexion
아키텍처: Actor (행동 생성), Evaluator (결과 평가), Self-Reflection 모듈 (개선 피드백 생성)의 세 가지 구성 요소로 이루어진 시스템입니다. 시도 간 에피소딕 메모리를 유지합니다.
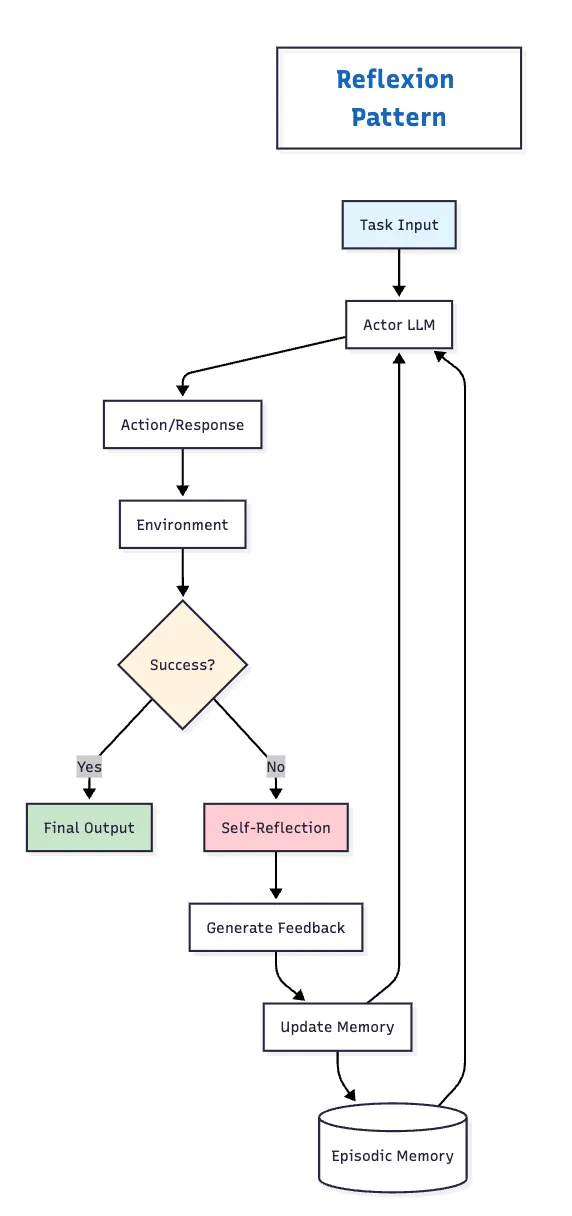
성능
- HumanEval: 88% pass@1 (GPT-4의 67% 대비)
- AlfWorld: 130/134 작업 완료
- 일반적으로 3–5회 반복 내 수렴
사용해야 할 때
- 테스트 케이스가 있는 프로그래밍 작업
- 순차적 의사결정 문제
- 명확한 성공 메트릭이 있는 작업
- 실패로부터 학습하는 것이 가치 있는 경우
- 반복적 개선 시나리오
제한사항
- 여러 시도 필요
- 신뢰할 수 있는 자기 평가 필요
- 원샷 작업에 적합하지 않음
멀티 에이전트 협업 패턴
5. Multi-Agent Debate (MAD)
아키텍처: 여러 에이전트가 솔루션을 제안하고, 구조화된 토론 라운드에 참여하며, 최종 결정을 위한 선택적 판사 에이전트를 포함합니다. 합의 강도를 처리하는 메커니즘을 포함합니다.
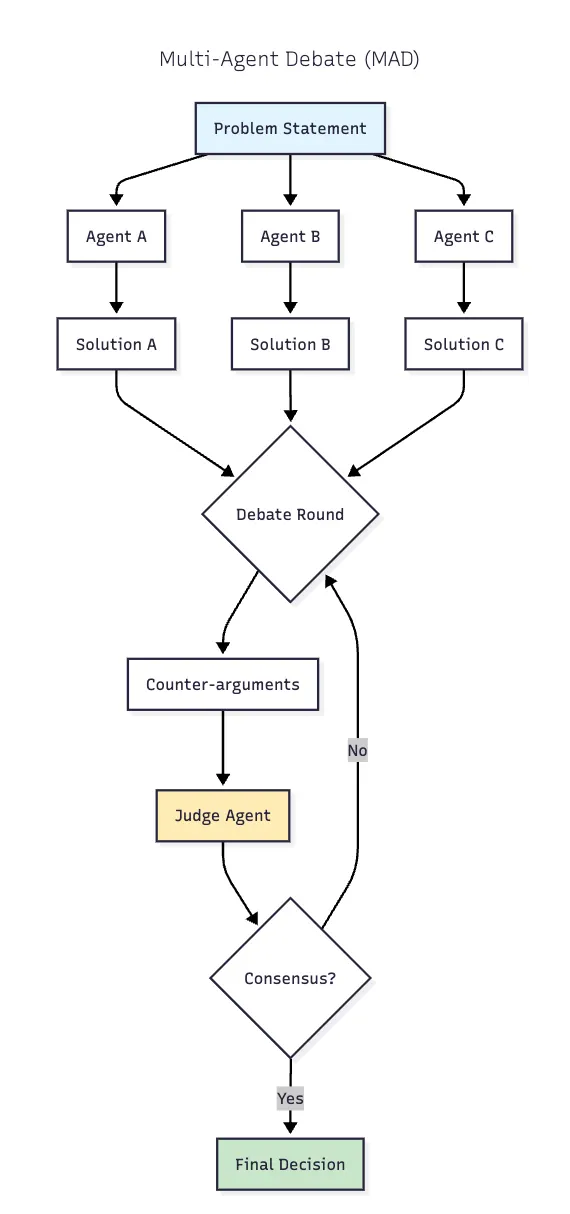
성능
- 싱글 에이전트 대비 15–47% 개선
- 최적 구성: 3–5개 에이전트
- 비용: 질문당 5–15 LLM 호출
사용해야 할 때
- 다양한 관점이 필요한 복잡한 추론
- 싱글 에이전트 편향에 취약한 문제
- 적대적 검증이 도움이 되는 작업
- 비용보다 정확성이 중요한 경우
제한사항
- 싱글 에이전트 대비 3–5배 더 비쌈
- 신중한 하이퍼파라미터 튜닝 필요
- 적절한 설정 없이 잘못된 합의로 수렴할 수 있음
증강 패턴
6. Tool-Use Pattern (Function Calling)
아키텍처: LLM이 외부 도구(계산기, 검색, 데이터베이스, 코드 실행)를 호출할 시점을 결정합니다. 현대적인 구현은 구조화된 출력을 사용한 함수 호출을 사용합니다.
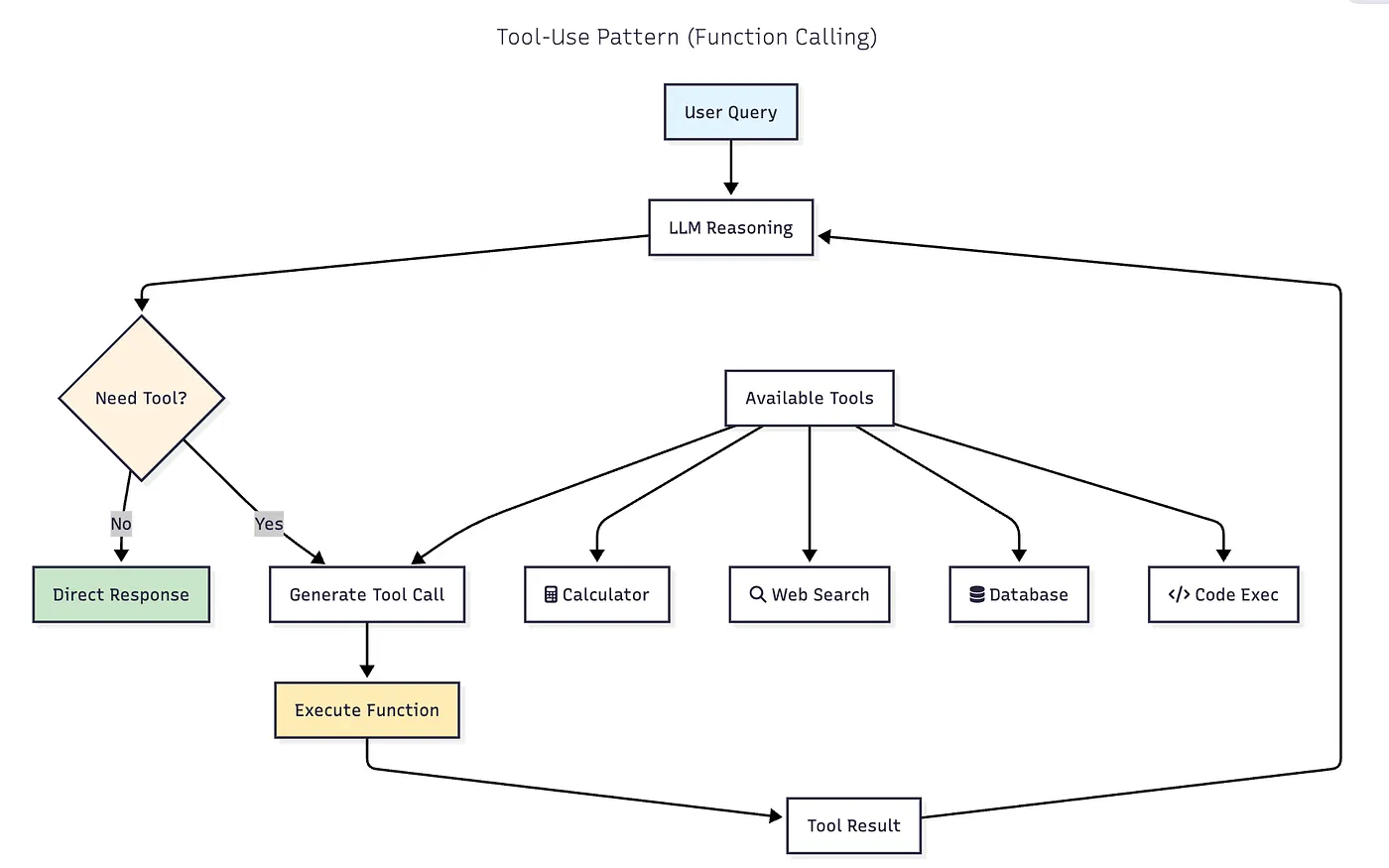
성능:
- 수학 작업: 25–40% 개선
- 실시간 쿼리: 60–80% 개선
- 함수 호출 정확도: GPT-4o (84.1%), Claude-3.5 (82.9%)
- 지연 시간: 도구 호출당 +0.5–2.0초
사용해야 할 때
- 실시간 데이터가 필요한 작업
- 수학적 계산
- 데이터베이스 쿼리
- 외부 기능이 필요한 모든 작업
- 특정 도메인의 정확성이 중요한 경우
제한사항
- 도구 호출당 추가 지연 시간
- 오류 전파 가능성
- 신중한 도구 설계 필요
7. Memory Systems
아키텍처: OS 디자인에서 영감을 받은 계층적 메모리입니다. 세 가지 계층: 작업 메모리 (활성 컨텍스트), 주 메모리 (최근 기록), 아카이브 (검색이 포함된 장기 저장소).
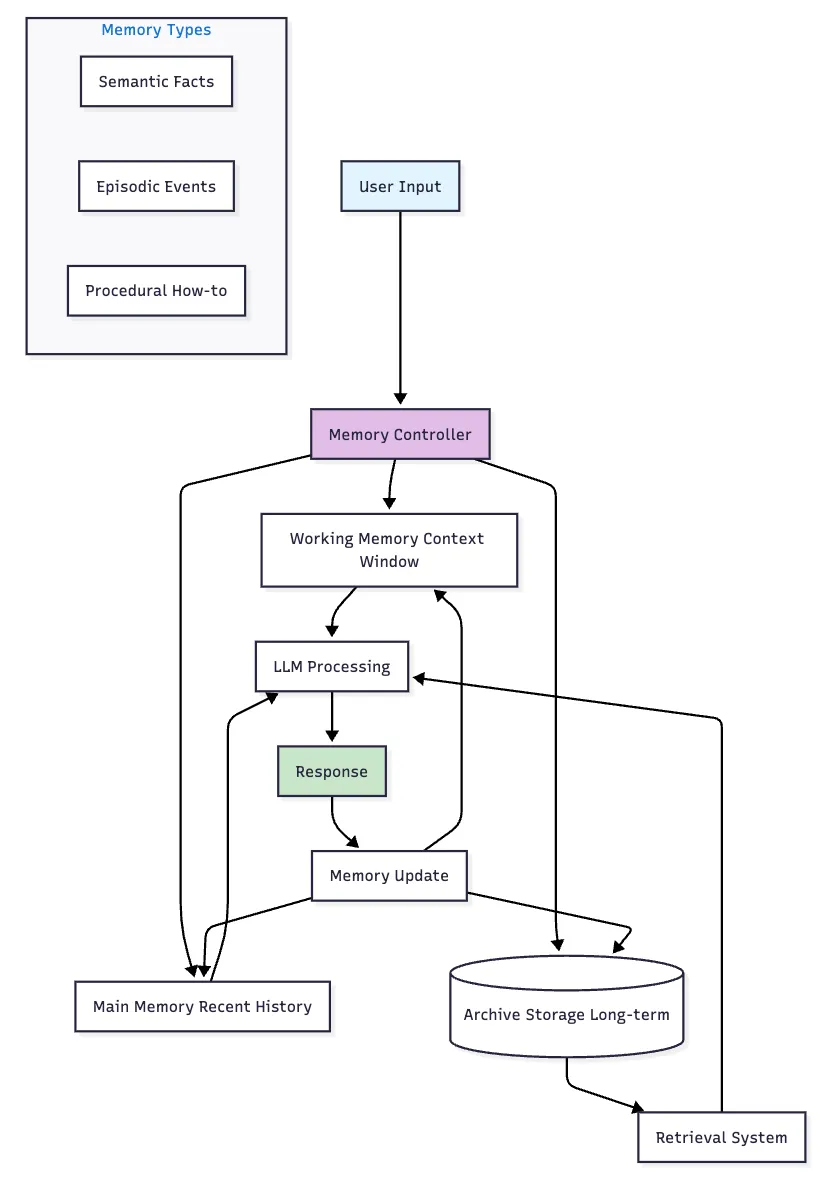
주요 구
- MemGPT: 가상 컨텍스트 관리, 100배 컨텍스트 윈도우 처리
- Mem0: OpenAI Memory 대비 26% 더 높은 정확도, 91% 더 낮은 지연 시간
메모리 유형별 성능:
- 의미적 메모리: 사실적 일관성에서 40–60% 개선
- 에피소딕 메모리: 작업 완료에서 35–50% 개선
- 절차적 메모리: 복잡한 실행에서 20–35% 개선
사용해야 할 때
- 다중 세션 애플리케이션
- 장기 컨텍스트가 필요한 작업
- 개인화 시스템
- 상태가 있는 복잡한 워크플로우
- 기록이 있는 채팅 애플리케이션
제한사항
- 저장 및 검색 오버헤드
- 메모리 관리의 복잡성
- 오래된 정보 가능성
고급 패턴
8. MCTS-Based Reasoning (MASTER)
아키텍처: LLM에 적용된 몬테 카를로 트리 검색입니다. 핵심 혁신: 시뮬레이션 단계를 제거하고 LLM 자기 평가를 대신 사용합니다. 에이전트 수를 동적으로 조정합니다.
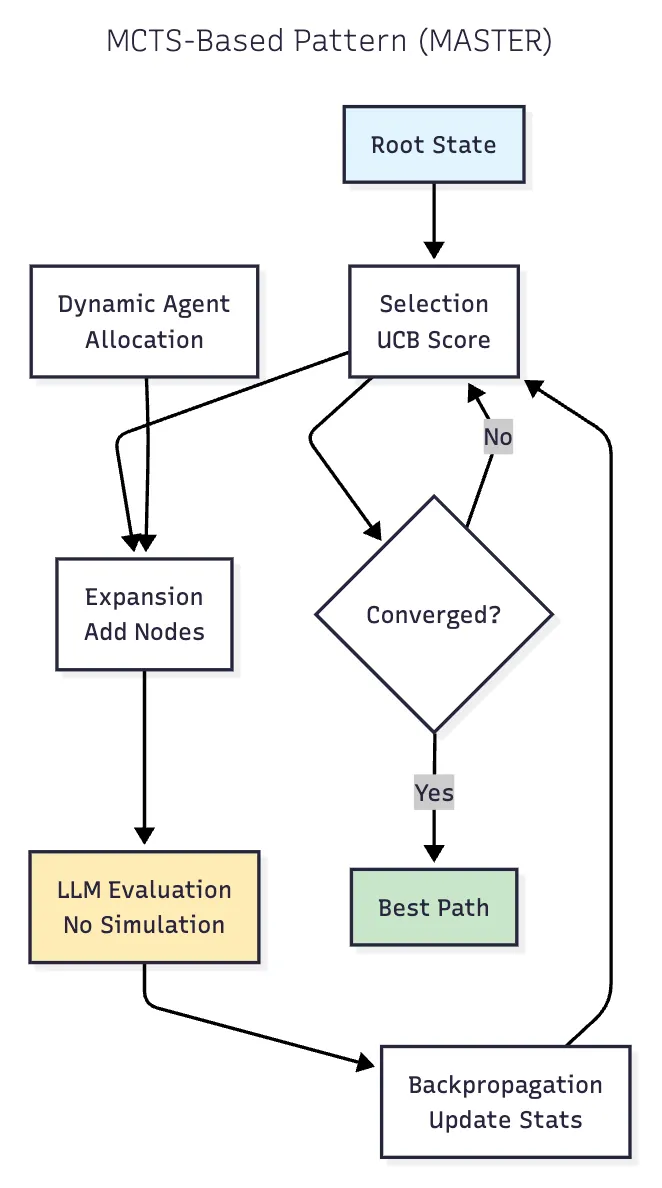
성능:
- HotpotQA: 76% 정확도 (SOTA)
- WebShop: 80% 성공률 (SOTA)
- Zero-shot CoT 대비 40.59% 개선
사용해야 할 때
- 복잡한 다단계 추론
- 큰 검색 공간을 가진 문제
- 선행 조회가 도움이 되는 작업
- SOTA 성능이 필요한 경우
- 연구 및 경쟁 시나리오
제한사항
- 높은 계산 비용
- 복잡한 구현
- 좋은 가치 추정 필요
9. Self-Improving Agents
아키텍처: 성능에 기반하여 자신의 코드/프롬프트를 수정하는 에이전트입니다. 배포 전 샌드박스 테스트와 경험적 검증을 포함합니다.
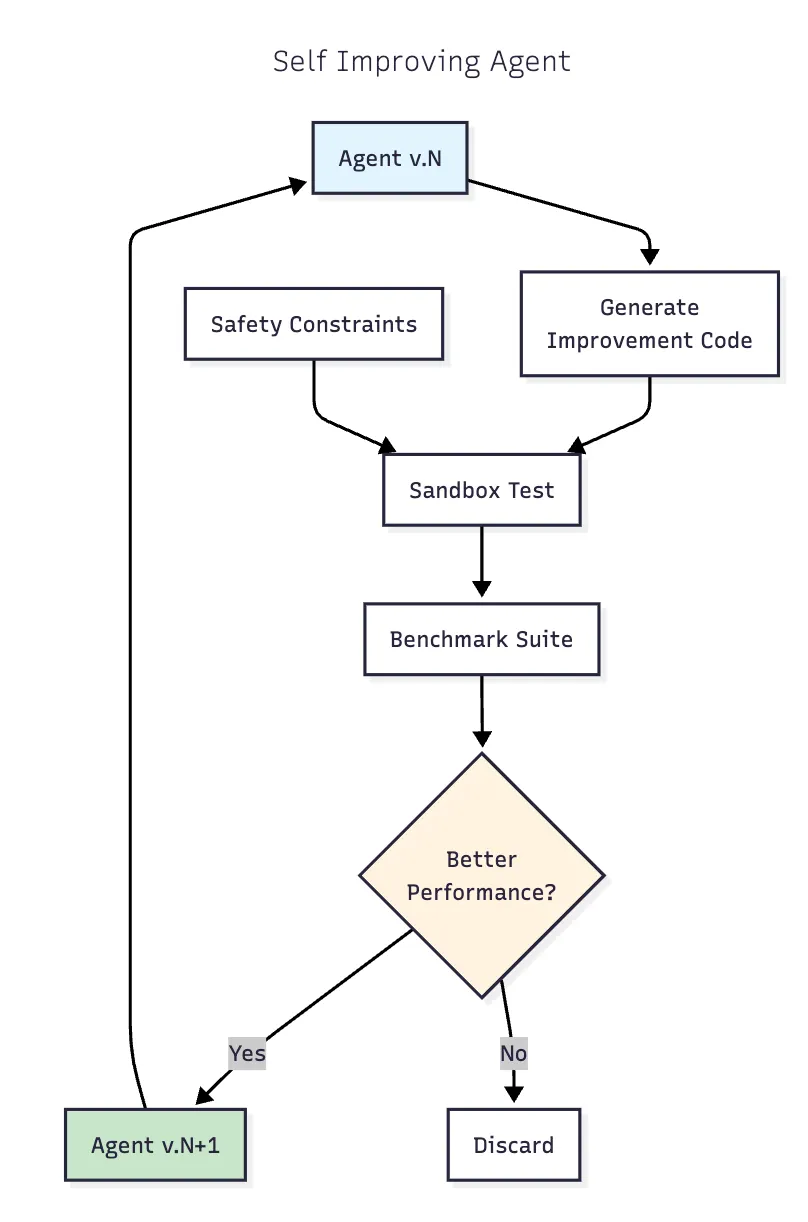
성능 (Darwin Gödel Machine):
- SWE-bench: 20.0% → 50.0%
- Polyglot: 14.2% → 30.7%
- 시간이 지남에 따라 지속적인 개선
사용해야 할 때
- 장기 실행 시스템
- 요구사항이 변화하는 작업
- 연구 환경
- 인간의 감독이 제한된 경우
- 실험적 AI 시스템
제한사항
- 안전성 우려
- 예측 불가능한 동작
- 광범위한 샌드박싱 필요
- 안전장치 없이 프로덕션에 적합하지 않음
하이브리드 패턴
10. Adaptive Reasoning Orchestrator (ARO) — 권장
아키텍처: 작업 복잡성, 비용 제약, 성능 요구사항에 기반하여 다른 패턴을 동적으로 선택하고 결합하는 메타 패턴입니다. 패턴 선택 개선을 위한 학습 구성 요소를 포함합니다.
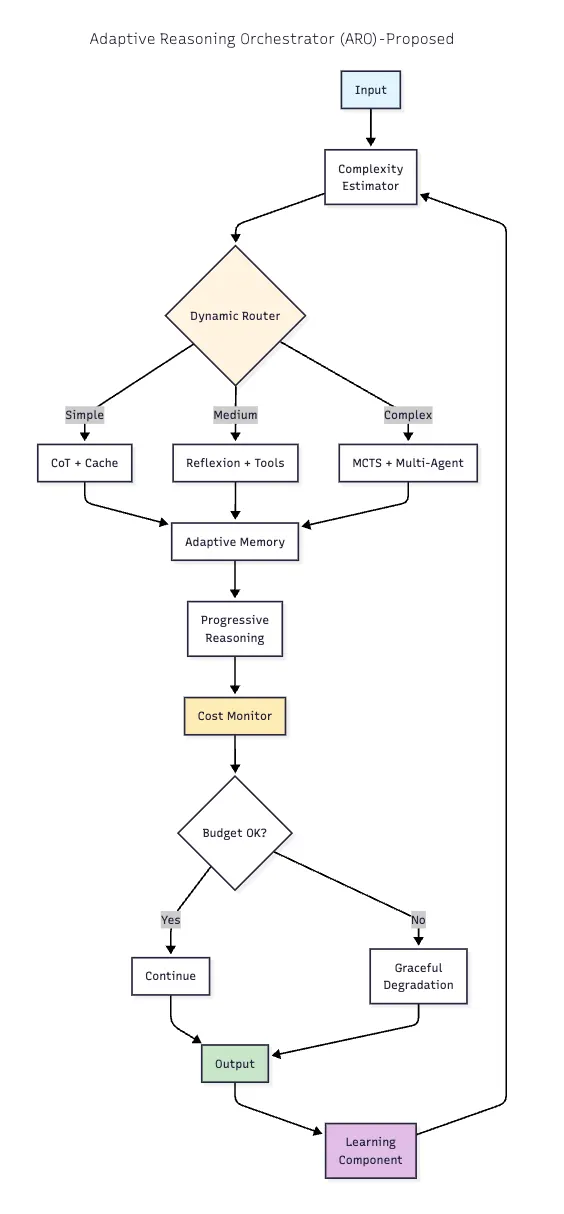
구성 요소:
- 복잡성 추정기
- 동적 라우터
- 비용 모니터
- 성능 분석
- 패턴 선택 ML
라우팅 로직:
- 간단한 작업 → CoT + 캐시
- 중간 복잡성 → Reflexion + 도구
- 높은 복잡성 → MCTS + 멀티 에이전트
사용해야 할 때:
- 다양한 워크로드를 가진 프로덕션 시스템
- 비용 최적화가 중요한 경우
- 혼합 복잡성 작업이 있는 애플리케이션
- 적응성이 필요한 시스템
- 엔터프라이즈 배포
장점:
- 최적의 비용/성능 균형
- 사용 패턴에서 학습
- 부하 하에서 우아한 성능 저하
- 모든 패턴에 대한 통합 인터페이스
참고: 이는 기존 패턴의 분석과 프로덕션 요구사항을 기반으로 한 제안된 패턴입니다. 구현은 동적 선택 로직과 함께 기존 패턴의 요소를 결합할 것입니다.
의사결정 프레임워크
싱글 에이전트 패턴을 선택해야 할 때
- 작업 복잡성이 하나의 모델로 관리 가능한 경우
- 해석 가능성이 중요한 경우
- 계산 예산이 제한된 경우
- 실시간 응답이 필요한 경우
멀티 에이전트 패턴을 선택해야 할 때
- 문제가 다양한 관점에서 이익을 얻는 경우
- 정확성이 중요한 경우
- 복잡한 도메인 전문성이 필요한 경우
- 비용이 성능보다 덜 중요한 경우
증강 패턴을 선택해야 할 때
- 외부 기능이 필요한 경우 (도구)
- 장기 컨텍스트가 중요한 경우 (메모리)
- 작업별 정확성이 중요한 경우
고급 패턴을 선택해야 할 때
- SOTA 성능이 필요한 경우
- 연구 또는 실험적 컨텍스트
- 학습 요구사항이 있는 장기 배포
프로덕션 고려사항
- 간단하게 시작: CoT로 시작하고, 필요할 때만 복잡성 추가
- 모든 것을 측정: 패턴당 정확성, 지연 시간, 비용 추적
- 적극적으로 캐싱: 특히 CoT 및 도구 응답에 대해
- 비용 한계 설정: 비싼 패턴에 대한 서킷 브레이커 구현
- A/B 테스트: 실제 워크로드에서 패턴 비교
- 성능 저하 모니터링: 패턴 성능 감소 주시
현재 도입 현황: 조사된 전문가의 51%가 프로덕션에서 에이전트를 적극적으로 사용하고 있으며, 78%가 활성 구현 계획을 가지고 있습니다.
구현 팁
- 패턴 조합: 많은 패턴이 함께 잘 작동합니다 (예: CoT + 도구, 메모리 + 멀티 에이전트)
- 폴백 전략: 복잡한 패턴에서 간단한 패턴으로 우아한 성능 저하 구현
- 프롬프트 엔지니어링: 각 패턴은 특정 프롬프트 형식을 필요로 할 수 있음
- 평가 메트릭: 패턴 선택 전 명확한 성공 기준 정의
- 프레임워크 선택: LangChain (63% 도입), AutoGen (Microsoft), 또는 AutoGPT를 필요에 따라 고려
직접 시도해 보기
시작하기:
pip install agentic-pattern'AI > LLM 서비스 개발' 카테고리의 다른 글
| LoRA, QLoRA, SFT, DPO, vLLM, 멀티 LoRA 서빙 (0) | 2026.03.31 |
|---|---|
| AI 엔지니어의 문제 정의 능력과 데이터 전략 (0) | 2026.03.30 |
| 파인 튜닝 (1) | 2026.03.23 |
| 프롬프트 엔지니어링 (0) | 2026.03.23 |
| 언어 모델 (Language Model) (0) | 2026.03.17 |