
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 애자일기법
- 자바
- database
- 코딩
- 프레임워크
- 그리디알고리즘
- 기술블로그
- ES
- Elasticsearch
- 백준
- 클린코드
- framework
- Java
- kotlin
- cleancode
- 알고리즘
- 개발
- JPA
- 개발자
- 데이터베이스
- AI
- spring boot
- 그리디
- 스프링
- 코드
- 엘라스틱서치
- Baekjoon
- 코딩테스트
- API
- Spring
- Today
- Total
튼튼발자 개발 성장기🏋️
[공모전] 1위의 빛나는 Butler 본문
Butler: AI 기반 통합 워크플로우 관리 시스템 구축기

목차
- 1. 개요
- 1.1. 왜 사용해야하는가?
- 2. 설계
- 2.1. 백엔드 설계
- 2.2. 프론트엔드 설계
- 2.3. MCP 설계
- 2.4. 인프라 설계
- 2.5. CI/CD 설계
1. 개요
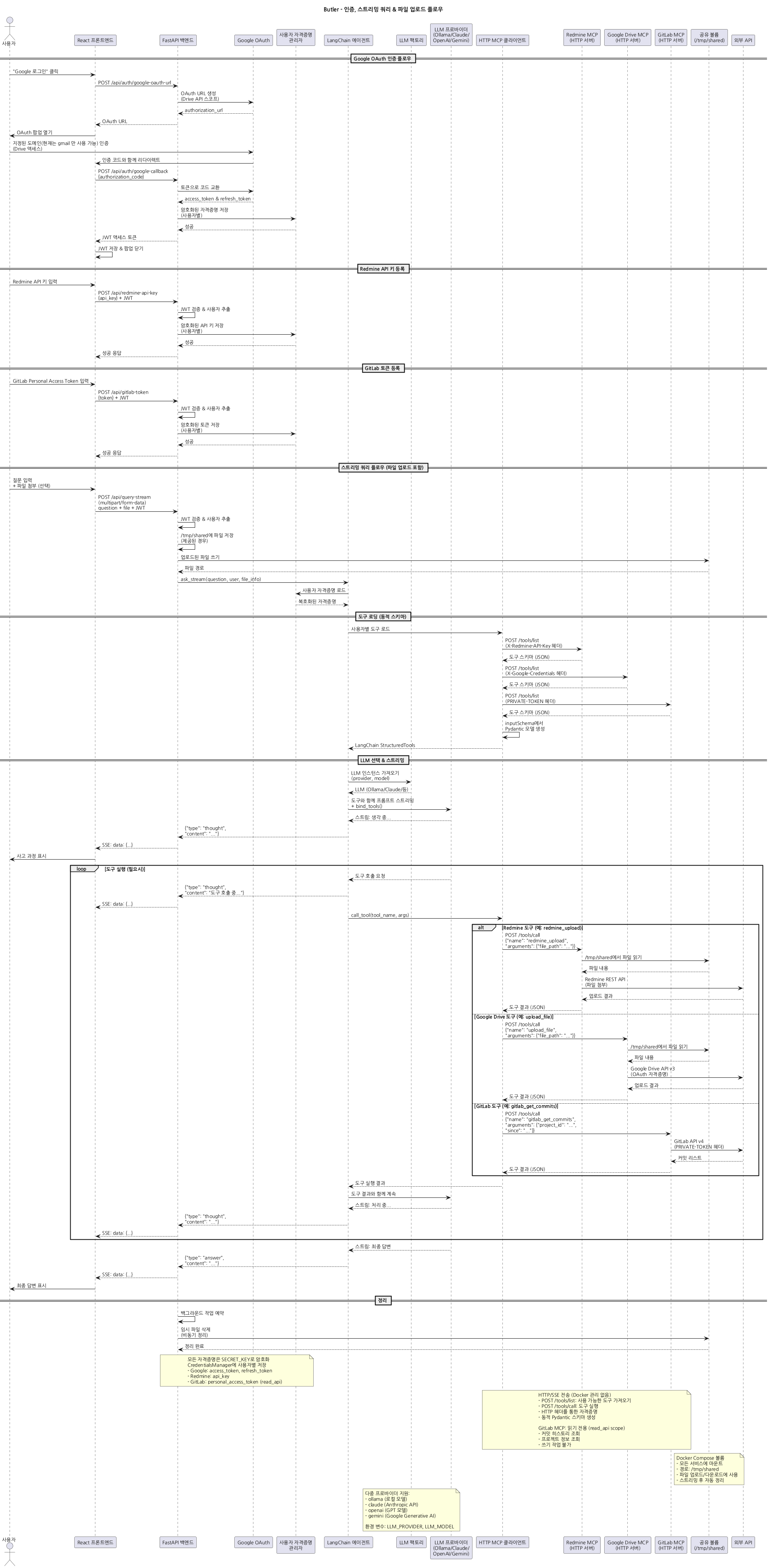
Butler는 Google Drive, Redmine, GitLab 세 가지 외부 서비스를 하나의 자연어 인터페이스로 통합한 AI 기반 질의응답 및 업무 대행 시스템입니다. 사용자는 "구글드라이브에서 A팀의 2025년 3분기 회식 정보를 찾아줘", "레드마인에서 나에게 할당된 일감을 리스트업해줘", "이 파일을 레드마인 이슈 #1234에 첨부해줘"와 같은 자연어 명령을 통해 여러 플랫폼의 데이터를 검색하고, 파일을 업로드하며, 커밋 히스토리를 조회할 수 있습니다.
https://github.com/small-goliath/butler
GitHub - small-goliath/butler: 생성 및 질의응답 AI agent
생성 및 질의응답 AI agent. Contribute to small-goliath/butler development by creating an account on GitHub.
github.com
1.1. 왜 사용해야하는가?
1.1.1. 문제 상황: 분산된 정보와 컨텍스트 스위칭 비용
현대 소프트웨어 개발 조직은 다양한 플랫폼에 정보가 분산되어 있습니다:
- Google Drive: 문서, 기획서, 회의록 (Confluence 등)
- Redmine: 이슈 트래킹, 일감 관리 (Jira 등))
- GitLab: 소스 코드, 커밋 히스토리, 브랜치 관리 (github, svn 등)
개발자가 특정 정보를 찾기 위해서는:
- 각 플랫폼에 개별 로그인
- 플랫폼별 검색 문법 학습 (Google Drive의
type:document, Redmine의 필터, GitLab의 고급 검색) - 여러 창을 오가며 정보 수집
- 수동으로 정보 통합
이러한 컨텍스트 스위칭 비용은 하루 평균 30분 이상의 시간을 소비하게 만듭니다. 300명 조직 기준으로 월 3,000시간의 생산성 손실이 발생합니다.
1.1.2. Butler의 해결 방법
Butler는 다음과 같은 방식으로 문제를 해결합니다:
1) 단일 인터페이스 제공
- 하나의 채팅 인터페이스에서 모든 플랫폼 접근
- Google OAuth 한 번으로 Drive API 자동 획득
- Redmine API 키, GitLab Token은 설정 메뉴에서 한 번만 입력
2) 자연어 처리
- 검색 문법 학습 불필요
- "최근 배포 관련 문서 찾아줘" → AI가 자동으로 Google Drive 검색
- "나의 이번 주 할당 일감" → AI가 Redmine API 호출
3) 지능형 라우팅
- AI 에이전트가 질문을 분석하여 적절한 플랫폼 선택
- 여러 플랫폼에서 데이터를 가져와 통합된 답변 제공
- 예: "프로젝트 X의 최근 커밋과 관련 일감 보여줘" → GitLab + Redmine 동시 조회
4) 실시간 스트리밍 응답
- Server-Sent Events(SSE)를 통한 사고 과정 표시
- 사용자는 AI가 어떤 도구를 호출하는지 실시간으로 확인
- 신뢰성과 투명성 확보
5) 파일 업로드 지원
- 질문과 함께 파일 첨부
- "이 파일을 레드마인 이슈 #1234에 첨부해줘" → 자동 업로드
비용 최적화 옵션:
- Ollama 사용 시: $112.72/월 (99.2% 절감)
- Claude Haiku 사용 시: $1,260.22/월 (92% 절감)
생산성 효과:
- 컨텍스트 스위칭 시간 절약: 30분/일 × 300명 = 150시간/일
- 월 절약 시간: 3,000시간
2. 설계
시스템 아키텍처

시퀀스 다이어그램
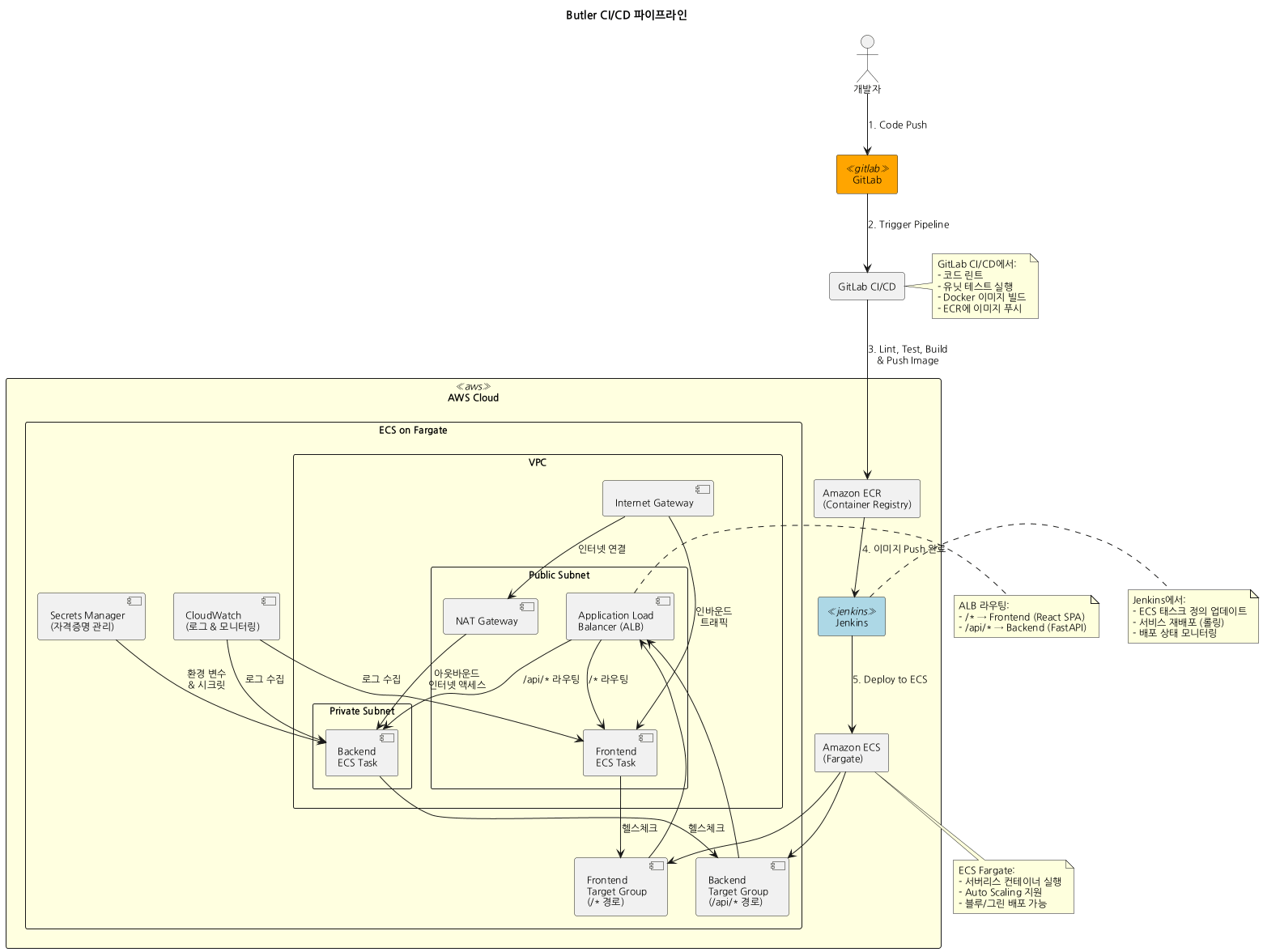
CI/CD Pipeline
2.1. 백엔드 설계
2.1.1. 프레임워크 선택: FastAPI vs Flask vs Django
| 기준 | FastAPI | Flask | Django |
| 타입 힌팅 | Pydantic 네이티브 | 별도 라이브러리 필요 | Django REST framework |
| 비동기 지원 | 네이티브 (ASGI) | 제한적 (WSGI) | 제한적 |
| OpenAPI 자동 생성 | 자동 | 수동 | DRF 필요 |
| SSE 지원 | StreamingResponse |
수동 구현 | 복잡 |
FastAPI 선택 이유
- Pydantic 통합: MCP 서버로부터 받은 JSON 스키마를 Pydantic 모델로 동적 생성
def create_langchain_tool_from_mcp(client: HTTPMCPClient, tool_info: Dict[str, Any]) -> StructuredTool:
properties = input_schema.get('properties', {})
field_definitions = {}
for prop_name, prop_info in properties.items():
python_type = str if prop_info.get('type') == 'string' else int
field_definitions[prop_name] = (python_type, Field(..., description=prop_desc))
ArgsSchema = create_model(f'{tool_name}_args', **field_definitions)- 비동기 스트리밍: SSE 기반 실시간 응답
- Flask는 yield를 사용할 수 있지만 WSGI 기반으로 동시성 처리가 제한적
- Django는 ASGI 지원이 있지만 설정이 복잡하고 오버헤드가 큼
# ...
async def event_stream():
async for chunk in agent_service.ask_stream(question_text, current_user, settings, file_info):
yield f"data: {json.dumps(chunk, ensure_ascii=False)}\n\n"
# ...
return StreamingResponse(event_stream(), media_type="text/event-stream")- 타입 안정성: LangChain과의 통합에서 타입 힌팅이 필수
- AgentExecutor의 입출력이 타입 지정되어 있어 FastAPI의 자동 검증 활용
2.1.2. 인증 방식: Google OAuth 2.0 vs SAML vs ID/PW
| 방식 | 장점 | 단점 | Butler 적합성 |
| ID/PW 방식 | 간단한 구현 | 비밀번호 관리 부담, 보안 취약 | ❌ |
| SAML | 엔터프라이즈 표준 | 복잡한 설정, IdP 필요 | ❌ |
| OAuth 2.0 | 토큰 기반, 외부 인증 위임 | 초기 설정 복잡 | ✅ |
Google OAuth 2.0 선택 이유
- Google Drive API 자동 획득: OAuth 인증 시
https://www.googleapis.com/auth/drive스코프를 요청하여 Drive API 권한을 동시에 획득scopes=[ 'openid', 'https://www.googleapis.com/auth/userinfo.email', 'https://www.googleapis.com/auth/userinfo.profile', 'https://www.googleapis.com/auth/drive' # Drive API 권한 ] - 도메인 제한 인증: ALLOW_EMAIL_DOMAIN 환경 변수로 특정 도메인만 접근 허용
if not email.endswith(settings.ALLOW_EMAIL_DOMAIN): raise HTTPException(status_code=403, detail=f"{settings.ALLOW_EMAIL_DOMAIN} 계정으로만 로그인할 수 있습니다.") - Refresh Token: 사용자가 재로그인 없이 장기간 사용 가능
- access_token 만료 시 refresh_token으로 자동 갱신
2.1.3. LangChain 에이전트 구조: ReAct vs Tool Calling
| 에이전트 타입 | 동작 방식 | 장점 | 단점 |
| ReAct | Thought → Action → Observation 루프 | 사고 과정 명확 | 반복 횟수 많음, 토큰 소비 높음 |
| Tool Calling | LLM이 직접 tool_calls 생성 | 효율적, 병렬 호출 가능 | LLM 지원 필요 |
Tool Calling Agent 선택 이유
- Claude 3.5 Sonnet의 네이티브 Tool Calling 지원: Anthropic API가 tools 파라미터를 통해 함수 호출을 최적화
- 토큰 효율성: ReAct는 매 단계마다 "Thought: ...", "Action: ..." 등의 텍스트를 생성하여 토큰 소비가 2-3배 높음
- 병렬 도구 호출: Tool Calling Agent는 여러 도구를 동시에 호출 가능 (예: Redmine + Google Drive 동시 조회)
2.1.4. 다중 LLM 프로바이더 지원: Factory 패턴
- 문제: 조직마다 선호하는 LLM이 다름 (비용, 성능, 보안)
- 해결: LLM Factory 패턴
class LLMFactory: def __init__(self, settings: Settings): provider = settings.LLM_PROVIDER.lower() if provider == "google": self._initialize_google(settings) elif provider == "ollama": self._initialize_ollama(settings) elif provider == "openai": self._initialize_openai(settings) elif provider == "claude": self._initialize_anthropic(settings)
장점:
- 환경 변수만으로 전환: LLM_PROVIDER=ollama → 즉시 Ollama 사용
- 비용 최적화: Claude → Ollama 전환 시 월 $13,770 → $0 (99.2% 절감)
- 벤더 락인 방지: LangChain의 BaseChatModel 인터페이스로 추상화
프로바이더별 특징:
| 프로바이더 | 비용 | Tool Calling | 스트리밍 | 사용 사례 |
| Ollama | 무료 | ✅ | ✅ | 내부망, 민감 데이터 |
| Claude | $3-15/1M tokens | ✅ 네이티브 | ✅ | 고품질 답변 필요 |
| OpenAI | $0.50-15/1M tokens | ✅ | ✅ | GPT 생태계 활용 |
| Gemini | $0.125-3.5/1M tokens | ✅ | ✅ | Google 서비스 통합 |
2.1.5. 사용자 자격증명 관리: 평문 저장 vs 해시 vs 대칭키 암호화 vs AWS Secrets Manager
| 방식 | 보안성 | 구현 복잡도 | Butler 선택 |
| 평문 저장 | ❌ 매우 낮음 | 낮음 | ❌ |
| 해시 (bcrypt) | ⚠️ 복호화 불가 (API 호출 불가) | 낮음 | ❌ |
| 대칭키 암호화 (Fernet) | ✅ 복호화 가능, 안전 | 중간 | ✅ |
| AWS Secrets Manager | ✅ 가장 안전 | 높음, 비용 증가 | ⚠️ (선택적) |
대칭키 암호화 (Fernet) 선택 이유
- 복호화 필요성: Redmine API 키, GitLab Token은 MCP 서버 호출 시 HTTP 헤더로 전달해야 하므로 복호화 가능해야 함
- AES-128 기반: Fernet은 AES-128-CBC + HMAC-SHA256으로 안전성 보장
- 간단한 키 관리: 환경 변수 SECRET_KEY 하나로 관리 (AWS Secrets Manager로 관리 가능)
- 사용자별 격리: user_data/{email}.json 파일로 분리하여 권한 침해 시 영향 최소화
2.1.6. 파일 업로드 처리: Base64 인코딩 vs Hex 인코딩 vs 공유 볼륨 vs S3 업로드
문제: 프론트엔드 → 백엔드 → MCP 서버로 파일 전달 시 네트워크 오버헤드
| 방식 | 장점 | 단점 | Butler 선택 |
| Base64 인코딩 | 구현 간단 | 파일 크기 33% 증가, 메모리 부담 | ❌ |
| Hex 인코딩 | 크기 증가 적음 | 여전히 2배 증가 | ⚠️ (대안) |
| 공유 볼륨 | 크기 증가 없음, 빠름 | Docker 볼륨 필요 | ✅ |
| S3 업로드 | 확장성 높음 | 비용, 지연 시간 | ❌ |
Docker 공유 볼륨 선택 이유
- 제로 오버헤드: 파일을 한 번만 저장, 메모리 복사 없음
- 대용량 파일 지원: Base64는 메모리 제한으로 10MB 이상 어려움, 볼륨은 수GB 가능
- 자동 정리: BackgroundTasks로 스트리밍 완료 후 삭제
2.2. 프론트엔드 설계
2.2.1. 프레임워크 선택: React vs Vue vs Svelte
| 기준 | React | Vue | Svelte |
| SSE 지원 | EventSource API | EventSource API | EventSource API |
| 타입 안전성 | TypeScript 네이티브 | Vue 3 + TS | TypeScript 지원 |
| 생태계 | 가장 큼 | 중간 | 작음 |
| 학습 곡선 | 중간 | 낮음 | 낮음 |
React 선택 이유
- 커뮤니티 크기: SSE 관련 예제가 가장 많고, 문제 해결이 빠름
- TypeScript 통합: 백엔드 Pydantic 모델과 프론트엔드 인터페이스를 일치시키기 용이
- Hooks API: useEffect를 통한 SSE 연결 관리
2.2.2. SSE(Server-Sent Events) vs WebSocket
| 기준 | SSE | WebSocket |
| 방향성 | 단방향 (서버 → 클라이언트) | 양방향 |
| 프로토콜 | HTTP/1.1, HTTP/2 | WebSocket (별도 프로토콜) |
| 재연결 | 자동 | 수동 구현 필요 |
| 브라우저 지원 | 모든 모던 브라우저 | IE 제외 |
| 프록시 호환성 | HTTP이므로 호환 | 일부 프록시 차단 |
SSE 선택 이유
- 단방향 통신 충분: Butler는 사용자가 질문을 보내면 백엔드가 스트리밍 응답을 하는 구조로, 클라이언트 → 서버 실시간 전송이 불필요
- 자동 재연결: 네트워크 끊김 시 브라우저가 자동으로 재연결
- HTTP 기반: ALB(Application Load Balancer)와 호환성이 높음
- 구현 간단: WebSocket은 연결 유지 로직이 복잡하지만 SSE는 fetch로 처리
2.2.3. OAuth 플로우: 팝업 vs 리다이렉트
| 방식 | 사용자 경험 | 보안 | 구현 복잡도 |
| 리다이렉트 | 페이지 전환, 상태 손실 | 높음 | 낮음 |
| 팝업 | 현재 페이지 유지 | 중간 (CORS 주의) | 중간 |
팝업 방식 선택 이유
- 상태 유지: 리다이렉트 방식은 채팅 기록이 사라지지만, 팝업은 메인 페이지가 유지됨
- 사용자 경험: 사용자는 로그인 중에도 메인 페이지를 볼 수 있음
- CSRF 방어: window.opener를 통한 메시지 전달로 origin 검증 가능
2.2.4. 파일 업로드: FormData vs JSON + Base64
| 방식 | 구현 | 파일 크기 제한 | 네트워크 효율 |
| JSON + Base64 | 간단 | ~5MB (JSON 파싱 부담) | 33% 오버헤드 |
| multipart/form-data | 표준 | ~10GB | 오버헤드 없음 |
multipart/form-data 선택 이유
- 표준 방식: multipart/form-data는 HTTP 표준으로 브라우저가 최적화
- 대용량 지원: Base64는 메모리에 전체 파일을 로드하지만, FormData는 스트리밍 전송
- FastAPI 통합: FastAPI의 UploadFile이 자동으로 파싱
2.3. MCP 설계
2.3.1. MCP(Model Context Protocol)란?
MCP는 Anthropic이 제안한 LLM 도구 통합 프로토콜로, AI 에이전트가 외부 데이터 소스에 접근하기 위한 표준화된 인터페이스입니다.
전통적인 방식 vs MCP:
| 전통적 방식 | MCP 방식 |
| 각 서비스마다 LangChain Tool 개별 구현 | MCP 서버가 도구 목록 제공 (/tools/list) |
| 하드코딩된 함수 시그니처 | JSON 스키마로 동적 생성 |
| 백엔드에 모든 API 키 저장 | MCP 서버가 자격증명 관리 |
2.3.2. MCP 전송 방식 선택: HTTP/SSE vs stdio
Anthropic의 공식 MCP는 stdio 기반:
# 공식 MCP 예제 (stdio)
from mcp import Server
server = Server("my-mcp-server")
@server.tool()
def my_tool(arg: str) -> str:
return "result"
if __name__ == "__main__":
server.run() # stdin/stdout 통신문제점:
- 프로세스 관리 복잡: 백엔드가 각 MCP 서버 프로세스를 spawn하고 관리해야 함
- Docker 환경 부적합: stdio는 같은 호스트에서만 가능, 컨테이너 간 통신 어려움
- 확장성 제한: 프로세스당 1개 연결, 동시 사용자 처리 불가
HTTP/SSE 전송 방식 선택 이유
- Docker 네이티브: 각 MCP 서버는 독립 컨테이너로 실행, Service Discovery로 통신
- 수평 확장: ALB를 통해 MCP 서버를 여러 인스턴스로 확장 가능
- 프로세스 관리 불필요: ECS Fargate가 컨테이너 생명주기 관리
- 사용자별 자격증명: HTTP 헤더로 전달 (X-Redmine-API-Key, X-Google-Credentials)
2.3.3. 동적 스키마 생성: Pydantic 동적 모델
문제: MCP 서버마다 도구 시그니처가 다름
기존 LangChain 방식 (하드코딩):
from langchain.tools import StructuredTool
from pydantic import BaseModel, Field
class RedmineRequestInput(BaseModel):
path: str = Field(..., description="API endpoint path")
method: str = Field("get", description="HTTP method")
redmine_tool = StructuredTool.from_function(
func=redmine_request,
name="redmine_request",
description="Make a request to the Redmine API",
args_schema=RedmineRequestInput
)Butler의 동적 생성
def create_langchain_tool_from_mcp(client: HTTPMCPClient, tool_info: Dict[str, Any]) -> StructuredTool:
tool_name = tool_info.get('name')
input_schema = tool_info.get('inputSchema', {})
properties = input_schema.get('properties', {})
required_fields = set(input_schema.get('required', []))
# Pydantic 필드 동적 생성
field_definitions = {}
for prop_name, prop_info in properties.items():
python_type = str if prop_info.get('type') == 'string' else int
if prop_name not in required_fields:
python_type = Optional[python_type]
field_definitions[prop_name] = (python_type, Field(None, description=prop_info.get('description')))
else:
field_definitions[prop_name] = (python_type, Field(..., description=prop_info.get('description')))
# 런타임에 Pydantic 모델 생성
ArgsSchema = create_model(f'{tool_name}_args', **field_definitions)
async def tool_func(**kwargs) -> str:
return await client.call_tool(tool_name, kwargs)
return StructuredTool.from_function(
coroutine=tool_func,
name=tool_name,
description=tool_info.get('description'),
args_schema=ArgsSchema
)장점:
- MCP 서버 추가가 쉬움: 새로운 MCP 서버를 추가해도 백엔드 코드 수정 불필요
- 타입 안정성: LangChain이 Pydantic 모델을 통해 인자 검증
- LLM 최적화: LLM이 도구 스키마를 보고 적절한 인자를 생성
2.3.4. 사용자별 자격증명 전달: HTTP 헤더
문제: 300명이 동시에 사용하는데, 각 사용자의 API 키가 다름
| 방식 | 보안 | 확장성 | 구현 |
| 환경 변수 | ❌ 모든 사용자가 같은 키 사용 | ❌ | 간단 |
| HTTP 헤더 | ✅ 사용자별 격리 | ✅ | 중간 |
| JWT + 백엔드 저장소 | ✅ 가장 안전 | ✅ | 복잡 |
HTTP 헤더 전달 방식 사용 이유
- 멀티테넌트 지원: 각 사용자가 자신의 자격증명으로 MCP 서버 호출
- 보안 격리: 사용자 A의 요청이 사용자 B의 데이터에 접근 불가
- 감사 추적: MCP 서버 로그에 API 키를 기록하여 누가 호출했는지 추적
2.3.5. GitLab MCP: 읽기 전용 설계
문제: GitLab의 쓰기 권한은 위험 (코드 삭제, 브랜치 강제 푸시 등)
| 권한 범위 | 가능한 작업 | 위험성 | Butler 선택 |
| api (full access) | 읽기 + 쓰기 + 삭제 | 높음 | ❌ |
| read_api | 읽기 전용 | 낮음 | ✅ |
| read_repository | 코드 읽기만 | 매우 낮음 | ⚠️ (커밋 히스토리 불가) |
read_api 권한만 요구
제공 도구 (모두 읽기 전용):
@mcp.tool()
def gitlab_list_projects(search: str = None, ctx: Context = None) -> str:
"""프로젝트 목록 조회"""
@mcp.tool()
def gitlab_get_commits(project_id: str, ref_name: str = None, ctx: Context = None) -> str:
"""커밋 히스토리 조회"""
@mcp.tool()
def gitlab_get_commit_diff(project_id: str, commit_sha: str, ctx: Context = None) -> str:
"""커밋 diff 조회"""
@mcp.tool()
def gitlab_get_branches(project_id: str, ctx: Context = None) -> str:
"""브랜치 목록 조회"""
@mcp.tool()
def gitlab_get_tags(project_id: str, ctx: Context = None) -> str:
"""태그 목록 조회"""
@mcp.tool()
def gitlab_get_contributors(project_id: str, ctx: Context = None) -> str:
"""컨트리뷰터 조회"""쓰기 도구 미제공:
- ❌ gitlab_create_branch
- ❌ gitlab_create_merge_request
- ❌ gitlab_delete_branch
선택 이유:
- 안전성 우선: AI가 잘못 판단해도 코드베이스에 영향 없음
- 사용 사례 부합: Butler의 주 목적은 정보 검색이지 코드 수정이 아님
2.4. 인프라 설계
2.4.1. 컨테이너 오케스트레이션: ECS Fargate vs EKS vs EC2
| 기준 | ECS Fargate | EKS (Kubernetes) | EC2 (Docker Compose) |
| 관리 부담 | 매우 낮음 (서버리스) | 높음 (클러스터 관리) | 중간 (인스턴스 관리) |
| 비용 | 중간 ($0.04656/vCPU-hour) | 높음 (컨트롤 플레인 $0.10/hour) | 낮음 (인스턴스 비용만) |
| 확장성 | 자동 (Task 기반) | 높음 (Pod 기반) | 수동 |
| 학습 곡선 | 낮음 | 매우 높음 | 중간 |
| 벤더 락인 | AWS 전용 | Kubernetes 표준 | 없음 |
ECS Fargate 선택 이유
- 서버리스: EC2 인스턴스 관리 불필요, AWS가 자동으로 프로비저닝
- 비용 효율: 300명 규모에서는 EKS 컨트롤 플레인 비용($72/월)이 부담
- 간단한 배포: Task Definition만 업데이트하면 자동 롤링 배포
- Auto Scaling: CPU/메모리 기반 자동 확장
2.4.2. 네트워크 구조: Public Subnet vs Private Subnet
문제: Backend는 Claude API를 호출해야 하고, Frontend는 사용자에게 노출되어야 함
| 구조 | 보안 | 비용 | 복잡도 |
| 모두 Public Subnet | 낮음 (모든 컨테이너 인터넷 노출) | 낮음 | 낮음 |
| 모두 Private Subnet | 높음 | 높음 (NAT Gateway) | 높음 |
| Public(Frontend) + Private(Backend) | 중간 | 중간 | 중간 |
네트워크 구조:
Internet
│
Internet Gateway
│
┌────────┴────────┐
│ │
Public Subnet Private Subnet
│ │
┌────┴────┐ ┌────┴────┐
│ ALB │ │ Backend │
└────┬────┘ │ MCP │
│ └────┬────┘
┌────┴────┐ │
│Frontend │ NAT Gateway
└─────────┘Public + Private 하이브리드 선택 이유
- 보안 격리:
- Backend는 Public IP가 없어 직접 접근 불가
- Backend → Claude API는 NAT Gateway를 통해 Private IP로 나감
- 비용 최적화:
- Frontend는 Public Subnet에 배치하여 NAT Gateway 불필요
- NAT Gateway는 Private Subnet용으로만 1개 (월 $43.07)
- 확장성:
- Backend를 여러 개로 늘려도 보안 그룹만 관리
2.4.3. Service Discovery: DNS vs IP 주소
문제: Backend가 MCP 서버에 어떻게 접근하는가?
| 방식 | 동적 IP 대응 | 구현 | Butler 선택 |
| 하드코딩 IP | ❌ (컨테이너 재시작 시 변경) | 간단 | ❌ |
| 환경 변수 IP | ❌ | 중간 | ❌ |
| AWS Service Discovery (Cloud Map) | ✅ (DNS 기반) | 중간 | ✅ |
| 외부 DNS (Route53) | ✅ | 복잡 | ⚠️ |
AWS Service Discovery 사용 이유
- 동적 IP 대응: ECS Task가 재시작되어도 DNS가 자동 업데이트
- 로드 밸런싱: 여러 Task가 실행되면 자동으로 라운드 로빈
- VPC 내부 통신: 인터넷을 거치지 않아 빠르고 안전
2.4.4. ALB(Application Load Balancer) 라우팅
문제: Frontend와 Backend가 같은 도메인에서 서비스되어야 CORS 문제 없음
| 방식 | CORS | 비용 | 복잡도 |
| 별도 도메인 (frontend.com, backend.com) | 필요 | ALB 2개 | 높음 |
| 서브도메인 (app.butler.com, api.butler.com) | 필요 | ALB 2개 | 중간 |
| 경로 기반 라우팅 (/, /api/) | 불필요 | ALB 1개 | 낮음 |
라우팅 규칙:
http://alb-dns-name/api/query-stream→ Backendhttp://alb-dns-name/api/auth/google→ Backendhttp://alb-dns-name/→ Frontendhttp://alb-dns-name/oauth/callback→ Frontend
경로 기반 라우팅 사용 이유
- CORS 불필요: 같은 Origin이므로 Access-Control-Allow-Origin 불필요
- 비용 절감: ALB 1개로 충분 (월 $17.25)
- 간단한 배포: Frontend 빌드를 Nginx에서 제공하면 됨
2.4.5. Secrets Manager vs 환경 변수
민감 정보:
- Google Client Secret
- JWT Secret Key
- Anthropic API Key
| 방식 | 보안 | 키 로테이션 | 비용 | Butler 선택 |
| 환경 변수 (평문) | ❌ 매우 낮음 | 수동 | 무료 | ❌ |
| 환경 변수 (암호화) | ⚠️ 낮음 (Task Definition에 노출) | 수동 | 무료 | ❌ |
| Secrets Manager | ✅ 높음 | 자동 | $1.20/월 | ✅ |
| Parameter Store (Secure String) | ✅ 중간 | 수동 | 무료 | ⚠️ |
데이터 민감도 정도에 따라 적절하게 나누어 사용
- 암호화 저장: 저장 시 KMS로 자동 암호화
- 접근 제어: IAM Policy로 Task Execution Role만 읽기 가능
2.4.6 인프라 비용 책정
2.4.1.1. 사용 가정
- 사용자 수: 300명
- 일일 쿼리 수: 100회/사용자
- 총 일일 쿼리: 30,000회
- 월간 쿼리: 900,000회
- 운영 시간: 24/7 (월 730시간)
2.4.1.2. AWS 인프라 비용 (Claude API 제외)
| 항목 | 월간 비용 (USD) | 계산 근거 |
| 1. ECS Fargate | $41.48 | 5개 서비스 × 0.25 vCPU × 0.5GB × 730h |
| 2. Application Load Balancer | $17.25 | $0.0225/h × 730h + 0.14 LCU × $0.008 × 730h |
| 3. NAT Gateway | $43.60 | $0.059/h × 730h + 9GB × $0.059 |
| 4. CloudWatch Logs | $6.99 | 9.1GB × $0.76 + 스토리지 |
| 5. Secrets Manager | $1.20 | 3개 × $0.40/secret |
| 6. ECR | $0.16 | 1.6GB × $0.10 |
| 7. VPC | $0.00 | 무료 |
| 8. 데이터 전송 (Outbound) | $2.04 | 16.2GB × $0.126 |
| AWS 인프라 소계 | $112.72 | ~$1,353/년 |
상세 계산:
1) ECS Fargate (서울 리전 가격)
가격:
- vCPU: $0.04656/vCPU-hour
- Memory: $0.00511/GB-hour
Backend (0.25 vCPU, 0.5 GB):
vCPU: 0.25 × $0.04656 × 730h = $8.50/월
Memory: 0.5 × $0.00511 × 730h = $1.87/월
Subtotal: $10.37/월
Frontend, MCP Redmine, MCP Google Drive, MCP GitLab (각각 동일):
4개 × $10.37 = $41.48/월2) Application Load Balancer
고정 비용: $0.0225/h × 730h = $16.43/월
LCU 계산 (Load Balancer Capacity Units):
- 신규 연결: 900,000 / (30 × 24 × 3600) ≈ 0.35/sec ≈ 0.14 LCU
- 데이터 처리: 9GB / 730h ≈ 0.012GB/h ≈ 0.012 LCU
- 규칙 평가: 2개 규칙 (frontend, backend) ≈ 0.002 LCU
최대 LCU: 0.14 LCU
LCU 비용: 0.14 × $0.008 × 730h = $0.82/월
Total: $16.43 + $0.82 = $17.25/월3) NAT Gateway
고정 비용: $0.059/h × 730h = $43.07/월
데이터 처리 (Private Subnet → Internet):
- Backend → Claude API: 900,000 × 10KB = 9GB
- 9GB × $0.059 = $0.53/월
Total: $43.07 + $0.53 = $43.60/월4) CloudWatch Logs
로그 생성량:
- Backend: 5KB × 900,000 = 4.5GB/월
- Frontend: 2KB × 900,000 = 1.8GB/월
- MCP Redmine: 3KB × 450,000 = 1.4GB/월
- MCP Drive: 3KB × 450,000 = 1.4GB/월
Total: 9.1GB/월
수집 비용: 9.1GB × $0.76 = $6.92/월
스토리지 비용 (7일 보관): 9.1GB × (7/30) × $0.0324 = $0.07/월
Total: $6.92 + $0.07 = $6.99/월2.4.1.3. LLM API 비용 (Claude 3.5 Sonnet)
| 항목 | 월간 비용 (USD) | 계산 근거 |
| Claude API | $13,770.00 | Input: 1,890M × $3/1M + Output: 540M × $15/1M |
상세 계산:
쿼리당 평균 토큰:
- Input: 2,100 tokens (시스템 프롬프트 500 + 질문 100 + 도구 스키마 1,000 + 결과 500)
- Output: 600 tokens (사고 과정 200 + 도구 호출 100 + 답변 300)
월간 토큰:
- Input: 2,100 × 900,000 = 1,890M tokens
- Output: 600 × 900,000 = 540M tokens
비용:
- Input: 1,890M × $3.00/1M = $5,670/월
- Output: 540M × $15.00/1M = $8,100/월
Total: $13,770/월2.4.1.4. 총 비용 요약
| 구분 | 월간 비용 (USD) | 연간 비용 (USD) | 비율 |
| AWS 인프라 | $112.72 | $1,352.64 | 0.8% |
| Claude API | $13,770.00 | $165,240.00 | 99.2% |
| 총 합계 | $13,882.72 | $166,592.64 | 100% |
2.4.1.5. 비용 최적화 방안
1) LLM 프로바이더 변경
| 프로바이더 | 월 비용 | 절감액 | 절감율 |
| Claude 3.5 Sonnet (현재) | $13,770 | - | - |
| Claude 3 Haiku | $1,147.50 | $12,622.50 | 92% |
| Ollama (사내 서버) | $0 | $13,770 | 99.2% |
Claude 3 Haiku 계산:
Input: $0.25 / 1M tokens
Output: $1.25 / 1M tokens
Input: 1,890M × $0.25/1M = $472.50
Output: 540M × $1.25/1M = $675.00
Total: $1,147.50/월
최적화 후 총 비용: $112.72 (인프라) + $1,147.50 (Haiku) = $1,260.22/월
Ollama 사용 시:
추가 비용: $0 (기존 사내 서버 SEA-AI-OLLAMA-DEV-1 활용)
최적화 후 총 비용: $112.72/월
절감율: 99.2%
2) 인프라 Auto Scaling
피크 시간 (9-18시): 현재 규모 유지
비피크 시간: 각 서비스 0.5개로 축소
ECS Fargate 절감: $41.48 × 0.5 = $20.74/월
월 절감액: 약 $20/월
3) CloudWatch Logs 보관 기간 단축
현재: 7일
변경: 3일
예상 절감: $0.04/월 (미미함)2.5. CI/CD 설계
2.5.1. CI/CD 도구 선택: GitLab CI + Jenkins vs GitHub Actions vs Jenkins Only
| 도구 | 장점 | 단점 | Butler 선택 |
| GitLab CI + Jenkins | GitLab에서 빌드, Jenkins에서 배포 분리 | 복잡도 증가 | ✅ |
| GitHub Actions | 간단한 워크플로우 | 자체 호스팅 러너 필요 | ❌ |
| Jenkins Only | 단일 도구 | 파이프라인 정의 복잡 | ❌ |
GitLab CI (빌드) + Jenkins (배포) 사용 이유
- 책임 분리:
- GitLab CI: 코드 품질 (lint, test), 이미지 빌드 및 ECR 푸시
- Jenkins: ECS 배포 (Task Definition 업데이트, 서비스 재배포)
- GitLab CI의 강점:
- Docker-in-Docker 지원: services: [docker:dind]
- ECR 로그인 간편: aws ecr get-login-password | docker login
- 병렬 빌드: 5개 이미지를 동시 빌드
- Jenkins의 강점:
- ECS 배포 경험이 풍부한 팀
- 세밀한 배포 제어 (롤백, 특정 서비스만 배포)
2.5.2. GitLab CI 파이프라인 (.gitlab-ci.yml)
스테이지 구조:
stages:
- lint # 1단계: 코드 품질 검사
- test # 2단계: 유닛 테스트
- build # 3단계: 프론트엔드 빌드
- deploy # 4단계: Docker 이미지 빌드 및 ECR 푸시1) Lint 스테이지
lint-frontend:
stage: lint
image: node:24.3.0-slim
script:
- cd frontend
- npm install
- npm run lint # ESLint
rules:
- if: $CI_PIPELINE_SOURCE == 'merge_request_event'
- if: $CI_PIPELINE_SOURCE == 'push'
lint-backend:
stage: lint
image: python:3.13-slim
script:
- cd backend
- python -m venv .venv
- source .venv/bin/activate
- pip install -r requirements.txt
- ruff check . # Python linter
rules:
- if: $CI_PIPELINE_SOURCE == 'merge_request_event'
- if: $CI_PIPELINE_SOURCE == 'push'- Ruff: Python 린터 중 가장 빠름 (Rust 기반, Flake8보다 10-100배 빠름)
- ESLint: TypeScript 표준 린터
2) Test 스테이지
test-frontend:
stage: test
image: node:24.3.0-slim
script:
- cd frontend
- npm install
- npm run test # Jest + React Testing Library
test-backend:
stage: test
image: python:3.13-slim
script:
- cd backend
- python -m venv .venv
- source .venv/bin/activate
- pip install -r requirements.txt
- pytest # pytest
3) Build 스테이지 (프론트엔드만)
build-frontend:
stage: build
image: node:24.3.0-slim
script:
- cd frontend
- npm install
- npm run build # Vite 빌드 → dist/
artifacts:
paths:
- frontend/dist/
expire_in: 1 hour # 1시간 후 자동 삭제- 백엔드는 Docker 이미지 빌드 시 자동으로 빌드되므로 별도 스테이지 불필요
- 프론트엔드 dist/를 artifact로 저장하여 다음 스테이지에서 사용
4) Deploy 스테이지 (Docker 빌드 및 ECR 푸시)
build-and-push-images:
stage: deploy
image: docker:latest
services:
- docker:dind # Docker-in-Docker
needs:
- build-frontend # 프론트엔드 빌드 완료 후 실행
before_script:
- apk add --no-cache aws-cli
- aws ecr get-login-password --region $AWS_DEFAULT_REGION | docker login --username AWS --password-stdin $ECR_REGISTRY_URL
- docker buildx create --use # Multi-platform 빌드
script:
# Backend
- docker buildx build --no-cache --platform linux/amd64 -f backend/Dockerfile -t $ECR_BACKEND_IMAGE -t $ECR_BACKEND_IMAGE_LATEST --push .
# Frontend
- docker buildx build --platform linux/amd64 -f frontend/Dockerfile -t $ECR_FRONTEND_IMAGE -t $ECR_FRONTEND_IMAGE_LATEST --push .
# MCP Google Drive
- docker buildx build --platform linux/amd64 -f mcp/mcp-google-drive/Dockerfile -t $ECR_MCP_GDRIVE_IMAGE -t $ECR_MCP_GDRIVE_IMAGE_LATEST --push ./mcp/mcp-google-drive
# MCP Redmine
- docker buildx build --platform linux/amd64 -f mcp/mcp-redmine/Dockerfile -t $ECR_MCP_REDMINE_IMAGE -t $ECR_MCP_REDMINE_IMAGE_LATEST --push ./mcp/mcp-redmine
# MCP GitLab
- docker buildx build --platform linux/amd64 -f mcp/mcp-gitlab/Dockerfile -t $ECR_MCP_GITLAB_IMAGE -t $ECR_MCP_GITLAB_IMAGE_LATEST --push ./mcp/mcp-gitlab
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH # main 브랜치만- Docker buildx: Multi-platform 빌드 지원
- ECS Fargate는 linux/amd64만 지원
- Apple Silicon (M1/M2)에서 빌드한 linux/arm64 이미지는 Fargate에서 실행 불가
- --no-cache (Backend만):
- Backend는 Python 패키지 의존성이 자주 바뀌므로 캐시 사용 시 버그 발생 가능
- Frontend는 node_modules가 캐시되어 빌드 시간 단축
- 태그 전략:
- $CI_COMMIT_SHORT_SHA: 커밋 해시 (예: abc123)
- latest: 최신 이미지 (롤백 시 사용)
2.5.3. Jenkins 파이프라인 (Jenkinsfile)
파라미터:
parameters {
string(name: 'IMAGE_TAG', defaultValue: 'latest', description: '배포할 Docker 이미지의 태그')
booleanParam(name: 'DEBUG_MODE', defaultValue: false, description: '디버깅 모드 (순차 실행)')
choice(name: 'DEPLOY_TARGET', choices: ['all', 'backend', 'frontend', 'mcp-gdrive', 'mcp-redmine', 'mcp-gitlab'], description: '배포할 서비스 선택')
}병렬 배포:
stage('ECS 배포') {
parallel {
stage('backend ECS 배포') {
when {
anyOf {
expression { params.DEPLOY_TARGET == 'all' }
expression { params.DEPLOY_TARGET == 'backend' }
}
}
steps {
script {
deployECSService(
serviceName: ECS_BACKEND_SERVICE_NAME,
repoName: ECR_BACKEND_REPO_NAME,
imageTag: params.IMAGE_TAG
)
}
}
}
// Frontend, MCP 서버들도 동일한 패턴
}
}ECS 배포 함수:
def deployECSService(Map config) {
withCredentials([aws(credentialsId: AWS_CREDENTIALS_ID)]) {
def serviceName = config.serviceName
def repoName = config.repoName
def imageTag = config.imageTag
def newImage = "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/${repoName}:${imageTag}"
sh """
# 1. 클러스터 존재 확인
CLUSTER_OUTPUT=\$(aws ecs describe-clusters --region ${AWS_REGION} --clusters ${ECS_CLUSTER_NAME})
CLUSTER_STATUS=\$(echo "\${CLUSTER_OUTPUT}" | jq -r '.clusters[0].status')
if [ "\${CLUSTER_STATUS}" != "ACTIVE" ]; then
echo "ERROR: Cluster ${ECS_CLUSTER_NAME} does not exist or is not active"
exit 1
fi
# 2. 서비스 존재 확인
SERVICE_OUTPUT=\$(aws ecs describe-services --region ${AWS_REGION} --cluster ${ECS_CLUSTER_NAME} --services ${serviceName})
SERVICE_STATUS=\$(echo "\${SERVICE_OUTPUT}" | jq -r '.services[0].status')
if [ "\${SERVICE_STATUS}" != "ACTIVE" ]; then
echo "ERROR: Service ${serviceName} does not exist or is not active"
exit 1
fi
# 3. 현재 Task Definition ARN 가져오기
TASK_DEFINITION_ARN=\$(aws ecs describe-services --region ${AWS_REGION} --cluster ${ECS_CLUSTER_NAME} --services ${serviceName} --query 'services[0].taskDefinition' --output text)
# 4. Task Definition 상세 정보 가져오기
TASK_DEFINITION_JSON=\$(aws ecs describe-task-definition --region ${AWS_REGION} --task-definition "\${TASK_DEFINITION_ARN}" --query 'taskDefinition')
# 5. 새로운 Task Definition JSON 생성 (이미지만 업데이트)
NEW_TASK_DEF_JSON=\$(echo "\${TASK_DEFINITION_JSON}" | python3 -c 'import json,sys;d=json.load(sys.stdin);d["containerDefinitions"][0]["image"]="${newImage}";print(json.dumps({k: v for k, v in d.items() if k in ["family", "taskRoleArn", "executionRoleArn", "networkMode", "containerDefinitions",
"volumes", "placementConstraints", "requiresCompatibilities", "cpu", "memory", "tags"]}))')
# 6. 새 Task Definition 등록
NEW_TASK_INFO=\$(aws ecs register-task-definition --region ${AWS_REGION} --cli-input-json "\${NEW_TASK_DEF_JSON}")
NEW_TASK_DEF_ARN=\$(echo "\${NEW_TASK_INFO}" | python3 -c 'import json,sys;print(json.load(sys.stdin)["taskDefinition"]["taskDefinitionArn"])')
# 7. ECS 서비스 업데이트
aws ecs update-service --region ${AWS_REGION} --cluster ${ECS_CLUSTER_NAME} --service ${serviceName} --task-definition "\${NEW_TASK_DEF_ARN}" --force-new-deployment
"""
}
}- 기존 Task Definition 재사용: 환경 변수, 시크릿, CPU/메모리 설정을 유지하고 이미지만 변경
- Python JSON 파싱: jq보다 안정적으로 Task Definition 필터링
- 오류 처리: 클러스터/서비스 존재 여부를 미리 확인하여 명확한 에러 메시지 제공
2.5.4. 블루/그린 배포 vs 롤링 배포
| 방식 | 다운타임 | 롤백 속도 | 리소스 사용 | Butler 선택 |
| 롤링 배포 | 없음 | 느림 (재배포) | 기존 리소스 | ✅ |
| 블루/그린 | 없음 | 빠름 (트래픽 전환) | 2배 (신규 환경 필요) | ❌ |
롤링 배포 과정:
- 신규 Task 1개 시작 (총 2개)
- 신규 Task가 헬스체크 통과
- 기존 Task 1개 종료 (총 1개)
- 완료
롤링 배포 사용 이유
- 비용 효율: 블루/그린은 배포 중 리소스가 2배 필요 (월 $41.48 추가)
- 간단한 롤백: IMAGE_TAG를 이전 버전으로 변경하여 재배포
- 충분한 속도: Task 시작 시간 약 30초, 롤백 시간 약 1분
'프로젝트 > 토이프로젝트' 카테고리의 다른 글
| AI 코드리뷰 자동화 (vLLM + Gitlab + Google Chat) (0) | 2025.11.11 |
|---|---|
| 푸르지오 스마트홈 가전제어를 언어로 손쉽게 (ios) (2) | 2025.01.07 |
| #4. 코인 자동 매매 프로그램 만들기 (1) | 2022.02.28 |
| #3. 코인 자동 매매 프로그램 만들기 (1) | 2022.02.07 |
| #2. 코인 자동 매매 프로그램 만들기 (0) | 2022.02.07 |


