
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Elasticsearch
- 기술블로그
- ES
- spring boot
- 데이터베이스
- JPA
- 백준
- cleancode
- 자바
- 애자일기법
- framework
- 코딩
- 엘라스틱서치
- 클린코드
- 그리디
- 프레임워크
- 개발자
- 알고리즘
- 개발
- 그리디알고리즘
- API
- Spring
- Baekjoon
- database
- 코딩테스트
- kotlin
- 코드
- AI
- 스프링
- Java
- Today
- Total
튼튼발자 개발 성장기🏋️
카프카 상세 개념 본문
1. 토픽과 파티션
1.1 적정 파티션 개수
토픽은 카프카에서 데이터를 관리하는 기본 단위이며, 각 토픽은 여러 개의 파티션으로 구성된다. 파티션은 데이터의 분산을 가능하게 하며, 병렬 처리를 통해 성능을 최적화할 수 있다. 적정 파티션 개수를 결정하는 것은 매우 중요하다. 어떻게 설정하느냐에 따라서 성능을 좌우하기 때문이다. 적절한 파티션 개수는 다음 요소에 따라 결정된다.
- 프로듀서/컨슈머 수: 높은 병렬 처리를 위해 파티션 수를 컨슈머 스레드(혹은 프로세스) 수와 비슷하게 맞추는 것이 이상적이다.
- 데이터 처리량: 파티션 수가 많을수록 병목 현상이 줄어들며, 데이터 처리량이 증가한다.
- 브로커 수: 파티션은 브로커에 분산되므로 브로커의 수에 따라 파티션 수를 조정해야 한다.
- ISR(In-Sync Replicas)와 가용성: 파티션 수가 증가하면 ISR의 크기가 줄어들 수 있으며, 이에 따라 데이터 가용성에 영향을 미칠 수 있다.
프로듀서 전송 데이터량 < 컨슈머 데이터 처리량 x 파티션 개수
예를 들어,
프로듀서가 보내는 데이터가 초당 1,000 레코드이고, 컨슈머가 처리할 수 있는 데이터가 초당 100 레코드이면, 파티션 개수는 10개 적정 개수가 된다.
1.2 토픽 정리 정책(cleanup.policy)
카프카는 데이터 정리 정책으로 cleanup.policy를 제공한다. 이는 로그 세그먼트가 만료되었을 때 데이터를 어떻게 처리할지 결정하는 정책이다. 주요 옵션은 다음과 같다.
- delete: 기본 설정으로, 설정된 유지 기간(retention period)이 지나면 로그 세그먼트가 삭제된다. 이는 오래된 데이터를 자동으로 정리하여 디스크 사용량을 최적화한다.
- compact: 로그 압축(compaction)을 통해 같은 키를 가진 오래된 레코드를 삭제하고 최신 상태만 유지한다. 이는 주로 상태 저장(Stateful) 애플리케이션에서 유용하다.
토픽 삭제 정책(delete policy)
cleanup.policy 옵션을 delete로 설정함으로써 토픽 삭제를 활성화할 수 있다. 이 설정이 활성화된 경우, 관리자는 필요에 따라 토픽을 삭제하여 디스크 공간을 회수할 수 있다. 토픽의 데이터를 삭제할 때는 세그먼트 단위로 삭제된다. 세그먼트는 파티션마다 별개로 생성되며 세그먼트의 파일 이름은 오프셋 중 가장 작은 값이 된다. segment.bytes 옵션으로 1개의 세그먼트 크기를 정의할 수도 있다. segment.bytes 값보다 커질 경우에 기존에 적재하던 세그먼트 파일을 닫고 새로운 세그먼트를 열어서 데이터를 저장한다. 이 세그먼트를 액티브 세그먼트라고 한다.
삭제 정책이 실행되는 시점은 시간 또는 용량으로 나누어 설정할 수 있다. 시간 단위로 실행하고 싶다면 retention.ms 설정을 통해 밀리초 단위로 데이터를 유지하는 기간을 설정할 수 있다. 카프카는 일정 주기마다 세그먼트 파일의 마지막 수정 시간과 retention.ms 값을 비교하는데, 세그먼트 파일의 마지막 수정 시간이 retention.ms를 넘어가면 그 때 세그먼트가 삭제된다. 만약 용량 단위로 실행하고 싶다면 retention.bytes 설정을 통해 토픽의 데이터 크가가 retention.bytes 값을 넘어가면 세그먼트 파일을 삭제할 수 있도록 할 수 있다.
한 번 삭제된 데이터는 복구 불가능하다.

토픽 압축 정책(compact policy)
cleanup.policy 옵션을 compact로 설정함으로써 토픽 압축을 활성화 할 수 있다. 압축은 특정 조건에 따라 로그를 압축하여 같은 키를 가진 오래된 데이터를 삭제하고 최신 상태만 유지하게 한다. 이 방식은 주로 키-값 저장소와 같이 상태를 유지해야 하는 애플리케이션에 유용하며, 디스크 공간 절약과 빠른 데이터 조회가 가능하다.
압축의 시작 지점은 min.cleanable.dirty.ratio 옵션으로 설정할 수 있다. 이 옵션 값은 액티브 세그먼트를 제외한 세그먼트에 남아있는 데이터의 테일 영역과 헤드영역의 레코드 개수의 비율을 뜻한다.
- 테일 영역(Tail Section): 로그 압축이 적용된 부분으로, 주로 과거의 데이터를 포함하고 있다. 이 영역의 데이터는 압축이 완료되었기 때문에 케시지 키의 중복이 없다.
- 헤드 영역(Head Section): 아직 압축이 적용되지 않은 데이터가 포함되어 있기 때문에 메지지 키의 중복이 있을 수 있다. 헤드 영역은 데이터를 실시간으로 수신하는 부분이기 때문에, 데이터가 활발히 추가되고 수정된다. 이 영역은 나중에 테일 영역으로 이동하여 압축의 대상이 된다.

1.3 ISR(In-Sync-Replicas)
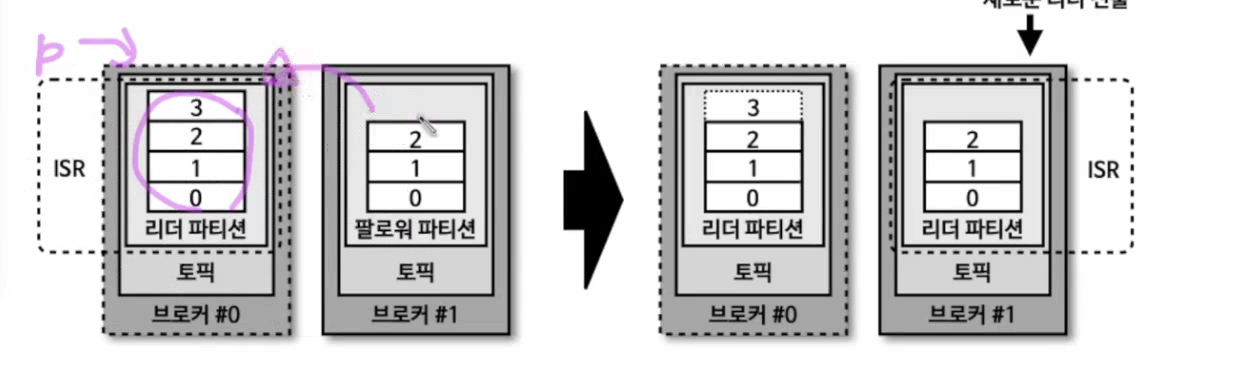
ISR(In-Sync Replicas)은 현재 리더 파티션과 동기화된 모든 복제본을 나타낸다. 리더 파티션은 ISR 중 하나이며, ISR 목록은 복제된 레코드가 모두 성공적으로 기록된 브로커를 포함한다. 만약 리더가 실패하면, ISR 내의 다른 복제본이 리더로 승격된다. ISR 크기는 가용성과 성능 간의 균형을 맞추는 중요한 요소다.
unclean.leader.election.enable
이 설정은 ISR 내의 모든 복제본이 동기화되지 않은 상태에서 리더를 선출할지를 결정한다. unclean.leader.election.enable값이 true로 설정되면, ISR에 없는 복제본도 리더로 승격될 수 있다. 이는 가용성을 높이지만 데이터 손실의 위험이 있다. 반대로, false로 설정하면 데이터 손실을 피할 수 있지만, 가용성은 낮아질 수 있다.
2. 카프카 프로듀서
2.1 acks 옵션
카프카 첫 시간에 등장했던 옵션 값이다. 프로듀서가 레코드를 브로커에 전송할 때, acks 옵션은 메시지 전송의 확인 여부를 설정한다.
- acks=0: 프로듀서는 브로커의 응답을 기다리지 않다. 성능이 좋지만 데이터 손실 위험이 있다.
- acks=1: 리더 파티션이 데이터를 수신하면 응답한다. 기본 설정으로 적절한 성능과 내구성 간의 균형을 제공한다.
- acks=all(또는 -1): ISR의 모든 복제본이 데이터를 수신해야만 응답한다. 가장 높은 내구성을 제공하지만, 성능이 떨어질 수 있다.
- min.insync.replicas: 프로듀서가 데이터를 전송할 때, ISR 내에서 최소 몇 개의 복제본이 동기화되어 있어야 하는지를 설정한다. 예를 들어, acks=all과 함께 min.insync.replicas를 2로 설정하면, 적어도 두 개의 복제본이 데이터를 수신해야만 성공적으로 전송된 것으로 간주된다.
2.2 멱등성 프로듀서(idempotence producer)
카프카의 멱등성 프로듀서는 중복된 메시지를 방지하여 데이터를 한 번만 정확히 전달하는 것을 보장한다. enable.idempotence를 true로 설정하면 정확히 한번 적재하는 로직이 성립되기 위해 프로듀서의 일부 옵션들이 강제로 설정되는데, 프로듀서의 데이터 재전송 횟수를 정하는 retries는 기본값으로 Integer.MAX_VALUE로 설정되고 acks옵션은 all로 설정된다.
이를 위해 카프카는 각 메시지에 고유의 프로듀서 번호(PID)와 시퀀스 번호(SID)를 부여하여 중복 메시지를 감지한다. 이 기능은 중복 메시지 전송의 위험이 있는 상황에서 데이터의 일관성을 유지하는 데 매우 유용하다. [그림 4]와 [그림 5]를 비교해보면 쉽게 이해할 수 있다.
SID는 1씩 증가하게 되는데, 만약 일정하지 않은 경우에는 OutOfOrderSequenceException이 발생하된다. 따라서 SID가 일정하지 않았을 경우를 예외처리하여 고려해야한다.


2.3 트랜잭션 프로듀서(transaction producer)
트랜잭션 프로듀서는 카프카에서 원자성(atomicity)을 보장하는 메시지 전송을 가능하게 한다. 여러 메시지를 하나의 트랜잭션으로 묶어, 모든 메시지가 성공적으로 전송되거나, 실패 시 모두 롤백되도록 한다. 이는 특히 금융 거래와 같이 데이터의 일관성과 무결성이 중요한 시스템에서 필수적인 기능이다.
트랜잭션 프로듀서는 트랜잭션 시작과 끝을 표현하기 위해 COMMIT이라는 트랜잭션 레코드를 한 개 더 보낸다. 이 또한 레코드 특성을 가지고 있기 때문에 파티션에 저장되어 오프셋을 한 개 차지한다.

3. 카프카 컨슈머
3.1 멀티 스레드 컨슈머

카프카는 기본적으로 각 컨슈머가 하나의 파티션만을 처리하도록 설계되어 있다. 그러나 멀티 스레드 환경에서 이를 효율적으로 활용하기 위해 여러 스레드로 파티션을 병렬로 처리할 수 있다. 이를 통해 데이터 처리량을 높이고, 소비자의 처리 능력을 최대화할 수 있다.
여러 프로세스를 사용할 것인지, 하나의 프로세스에서 여러 스레드를 사용할 것인지에 따라 고려해야할 부분이 많다. 멀티 스레드로 개발할 경우 하나의 컨슈머 스레드에서 예외가 발생할 경우 프로세스 자체가 종료될 수 있으며 다른 스레드에 영향이 갈 수 있다. 그렇게 되면 데이터 중복 처리라던가 데이터 유실까지도 이어질 수 있다.
3.2 카프카 컨슈머 멀티 워커 스레드 전략
멀티 워커 스레드 전략은 하나의 컨슈머 스레드가 여러 파티션으로부터 데이터를 가져오고, 별도의 워커 스레드가 이를 처리하는 구조다. 이 방식은 데이터 처리의 병목을 줄이고, 더 높은 처리량을 가능하게 한다. 각 워커 스레드는 독립적으로 작동하므로, 특정 워커에서 발생한 오류가 다른 워커의 처리에 영향을 미치지 않는다.
public class MultiWorkerConsumer {
private static final String TOPIC_NAME = "my-topic";
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String GROUP_ID = "my-consumer-group";
private static final int NUM_WORKERS = 4;
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
ExecutorService executor = Executors.newFixedThreadPool(NUM_WORKERS);
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
executor.submit(() -> {
processRecord(record);
});
}
}
} finally {
consumer.close();
executor.shutdown();
}
}
private static void processRecord(ConsumerRecord<String, String> record) {
System.out.printf("Processing record with key: %s, value: %s, partition: %d, offset: %d%n",
record.key(), record.value(), record.partition(), record.offset());
}
}3.3 카프카 컨슈머 멀티 스레드 전략
멀티 스레드 전략은 각 컨슈머 스레드가 독립적으로 파티션을 처리하는 방식이다. 이 전략은 병렬 처리를 극대화할 수 있지만, 각 스레드 간의 데이터 일관성을 유지하기 어려운 점이 있다. 이를 해결하기 위해 각 스레드가 동일한 파티션을 처리하지 않도록 파티션 할당을 주의 깊게 설계해야 한다.
KafkaConsumer 클래스는 Thread safe 하지 않기 때문에 스레드 별로 인스턴스를 만들어어 운영해야한다.
public class MultiThreadedConsumer implements Runnable {
private final KafkaConsumer<String, String> consumer;
public MultiThreadedConsumer(String bootstrapServers, String groupId, String topic) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
this.consumer = new KafkaConsumer<>(props);
this.consumer.subscribe(Collections.singletonList(topic));
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
processRecord(record);
}
}
} finally {
consumer.close();
}
}
private void processRecord(ConsumerRecord<String, String> record) {
System.out.printf("Thread %s: Processing record with key: %s, value: %s, partition: %d, offset: %d%n",
Thread.currentThread().getName(), record.key(), record.value(), record.partition(), record.offset());
}
public static void main(String[] args) {
int numConsumers = 3;
String bootstrapServers = "localhost:9092";
String groupId = "my-consumer-group";
String topic = "my-topic";
for (int i = 0; i < numConsumers; i++) {
Thread thread = new Thread(new MultiThreadedConsumer(bootstrapServers, groupId, topic));
thread.start();
}
}
}3.4 컨슈머 랙

컨슈머 랙은 컨슈머가 현재 처리하고 있는 오프셋과, 카프카 로그의 끝 오프셋(즉, 가장 최신 메시지) 간의 차이다. 이는 컨슈머가 얼마나 실시간 데이터를 따라잡고 있는지를 보여주는 중요한 지표다. 랙이 크면 컨슈머가 데이터를 따라잡지 못하고 있음을 의미하며, 이에 대한 조치가 필요할 것이다.
컨슈머 랙을 조회하는 방법은 3가지가 있다.
- 카프카 명령어를 사용하여 컨슈머 랙 조회: kafka-consumer-groups.sh 명령어를 사용하여 특정 컨슈머 그룹의 오프셋 정보를 확인하고, 각 파티션에서의 랙을 계산할 수 있다. 예를 들어, 다음과 같이 사용할 수 있다.이 방법은 일회성이기 때문에 모니터링하기에는 부족한 점이 많다.
kafka-consumer-groups.sh --bootstrap-server <broker> --describe --group <consumer-group> - 컨슈머 metrics() 메서드를 사용하여 컨슈머 랙 조회: 컨슈머 API를 통해 metrics() 메서드를 사용하여 컨슈머 랙을 조회할 수 있다. 이를 통해 프로그램 내에서 실시간으로 랙을 모니터링할 수 있으며, 이 정보를 기반으로 동적인 스케일링이나 경고 시스템을 구축할 수 있다. 이 방법은 컨슈머가 정상적으로 동작하고 있을 경우에만 확인이 가능하기 때문에 컨슈머가 다운되거나 정상적으로 동작하지 않을 경우에는 모니터링이 불가능하다.
- 외부 모니터링 툴을 사용하여 컨슈머 랙 조회: 외부 모니터링 툴은 컨슈머 랙을 시각화하고, 알림을 설정할 수 있는 강력한 기능을 제공한다. (카프카 버로우, 그라파나, 데이터독 등)
3.5 컨슈머 배포 프로세스
컨슈머의 배포는 안정성과 가용성을 보장하기 위해 신중하게 계획되어야 한다. 일반적으로 롤링 전략 및 블루/그린 배포 전략이나 카나리 배포 전략을 사용하여 새로운 버전의 컨슈머를 단계적으로 배포한다. 이 과정에서 트래픽을 모니터링하고, 문제가 발생하면 빠르게 롤백할 수 있는 메커니즘을 마련하는 것이 중요하다.
중단 배포
중단 배포는 기존 컨슈머를 완전히 중지한 후 새로운 버전의 컨슈머를 배포하는 방식이다. 이 방식은 간단하지만, 배포 과정에서 잠시 동안 서비스가 중단될 수 있는 위험이 있다. 따라서 이를 최소화하기 위해 배포 시간을 신중히 선택하고, 중단 시간을 최소화하는 것이 중요하다.
이 배포 방식은 유연한 인스턴스 발급이 어려운 물리 장비에서 운영하는 경우 등 한정된 서버 자원을 운영할 때 적합하다. 기존 컨슈머 애플리케이션이 완전이 종료되면 더는 토픽의 데이터를 가져갈 수 없기 때문에 컨슈머 랙이 늘어날 것이다. 그 말은 즉슨 지연이 발생한다는 이야기가 된다. 이 상황에서 신규 컨슈머 애플리케이션 배포가 늦어지면 컨슈머 랙이 증가하고 서비스 지연으로까지 이어질 수 있다.
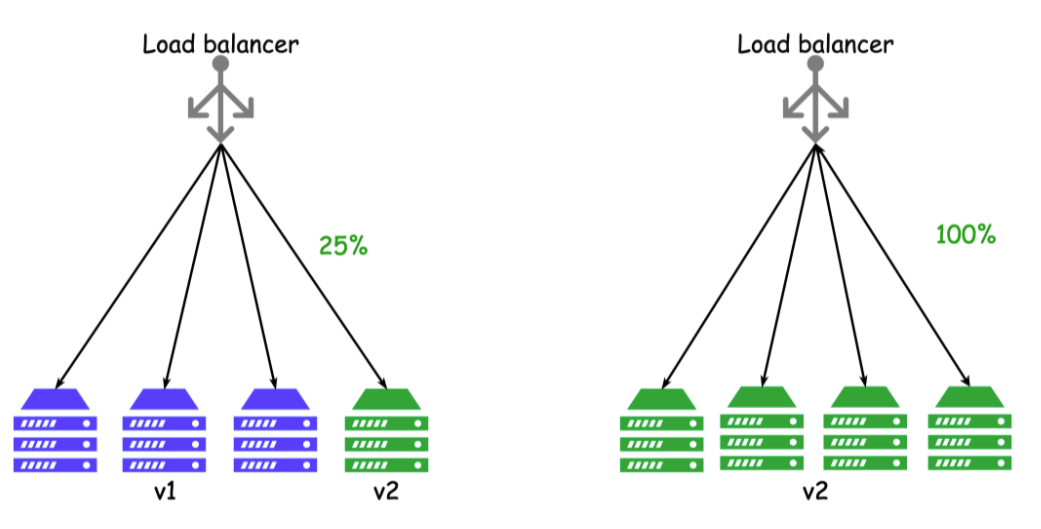
무중단 배포
무중단 배포는 서비스 중단 없이 새로운 버전의 컨슈머를 배포하는 전략이다. 이를 위해 롤링 업데이트나 블루/그린 배포 전략 등을 사용할 수 있다. 무중단 배포는 높은 가용성이 요구되는 시스템에서 필수적이며, 사용자가 서비스 중단을 느끼지 않도록 설계되어야 한다.


'기타 > apache kafka' 카테고리의 다른 글
| Kafka CDC: MySQL to MongoDB 동기화 #2 (3) | 2025.07.08 |
|---|---|
| Kafka CDC: MySQL to MongoDB 동기화 #1 (0) | 2025.07.05 |
| Kafka MirrorMaker 2 (0) | 2024.08.17 |
| 카프카 커넥트 (1) | 2024.08.17 |
| 카프카 스트림즈 (0) | 2024.08.11 |


